
# 业务开通
# 开通流程
使用开发者账号登录uniCloud控制台 ,选择uni-ai栏目。

阅读uni-ai服务协议并点击协议下方的“同意协议并开通”按钮,便可开通uni-ai服务。

# 购买套餐
uni-ai付费服务按月度套餐购买,您可以根据业务规模,选择合适的套餐下单。

# 套餐升级说明
为提供更优质的AI服务体验,我们将于2025年6月25日正式推出uni-ai新版套餐体系。现将升级事宜说明如下:
- 新套餐上线:2025年6月25日起,所有新购套餐将按照新版规范执行。
- 自动升级:对于在新版套餐上线前购买且仍在有效期内的旧版套餐,我们将自动为您升级至对应权益的新版套餐,无需任何操作。
- 计费单位变更:为优化计费体系,我们引入新的计费单位"utoken"替代原有的"token"概念。此次变更仅涉及概念名称调整,实际价值保持不变,即1 utoken = 1 token(旧版)。所有新版套餐中的utoken价值将与旧版套餐中的token保持完全一致,用户权益不受影响。什么是utoken?
新旧版本套餐内容如下所示:
| 版本 | utoken数(新版) | token数(旧版) | 售价 |
|---|---|---|---|
| 体验版 | 300K | 300K | 4.5元/月 |
| 45元套餐 | 3030K | 45元/月 | |
| 90元套餐 | 6080K | 90元/月 | |
| 450元套餐 | 30500K | 450元/月 | |
| 900元套餐 | 62000K | 900元/月 | |
| 1800元套餐 | 125000K | 1800元/月 | |
| 4500元套餐 | 315000K | 4500元/月 | |
| 9000元套餐 | 650000K | 9000元/月 | |
| 旗舰版套餐 | 1450000K | 20000元/月 |
# 安全配置
系统提供了 uniCloud 服务空间白名单安全配置,可以提高接口调用安全性,防止被他人盗用。可点击“添加服务空间”按钮,选择相应的服务空间完成添加服务空间白名单,服务空间添加成功后,只有列表中的服务空间才可以调用当前账号下的uni-ai接口。此列表为空时,不校验调用方的服务空间。
# 调用记录
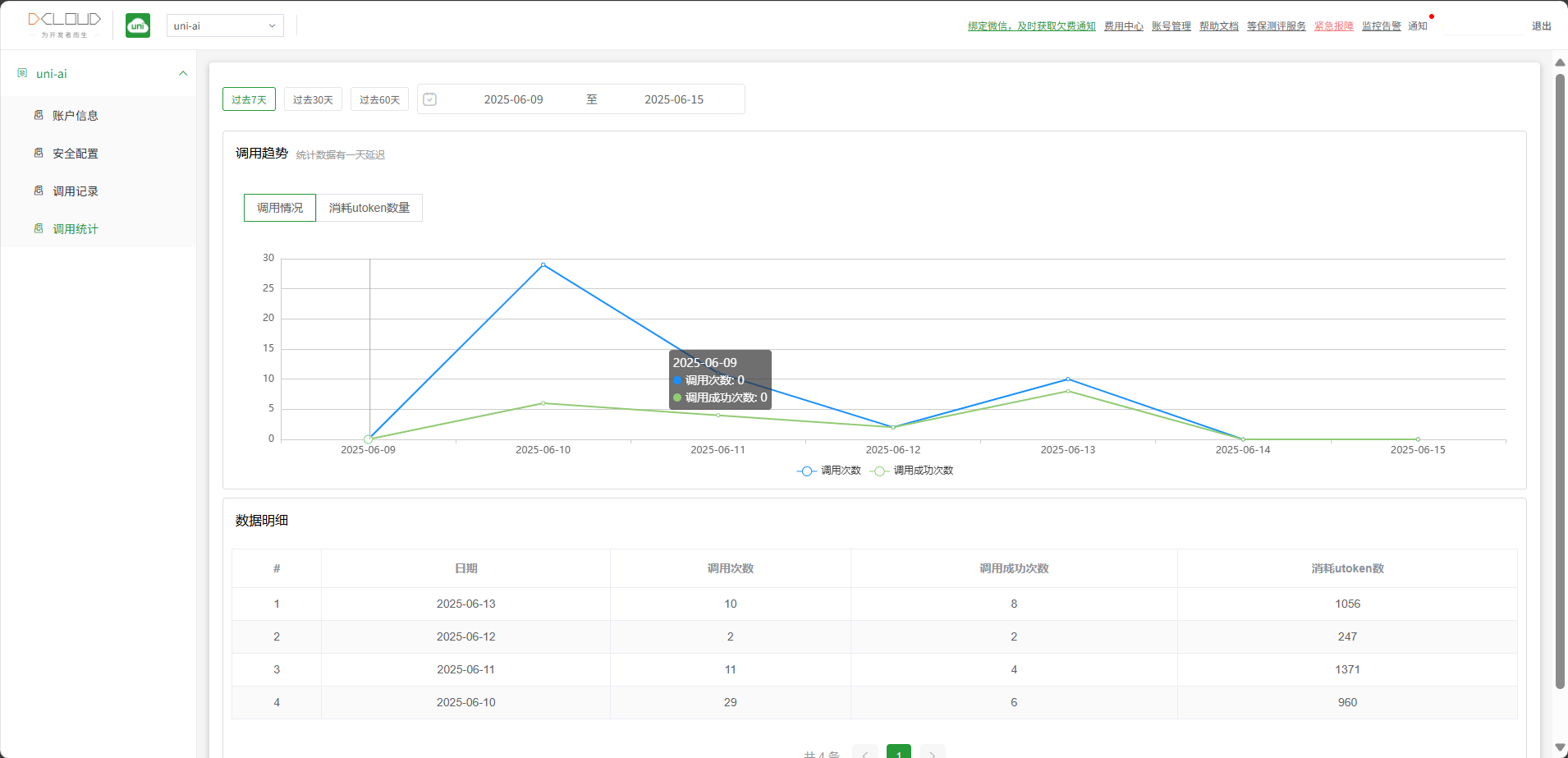
系统可查看uni-ai接口每日调用汇总数据,包括每日调用次数、每日调用成功次数、每日消耗token数等汇总数据。

# 调用统计
系统可查看uni-api接口每日调用汇总数据,包括每日调用次数、每日调用成功次数、每日消耗token数等汇总数据。
# 套餐说明
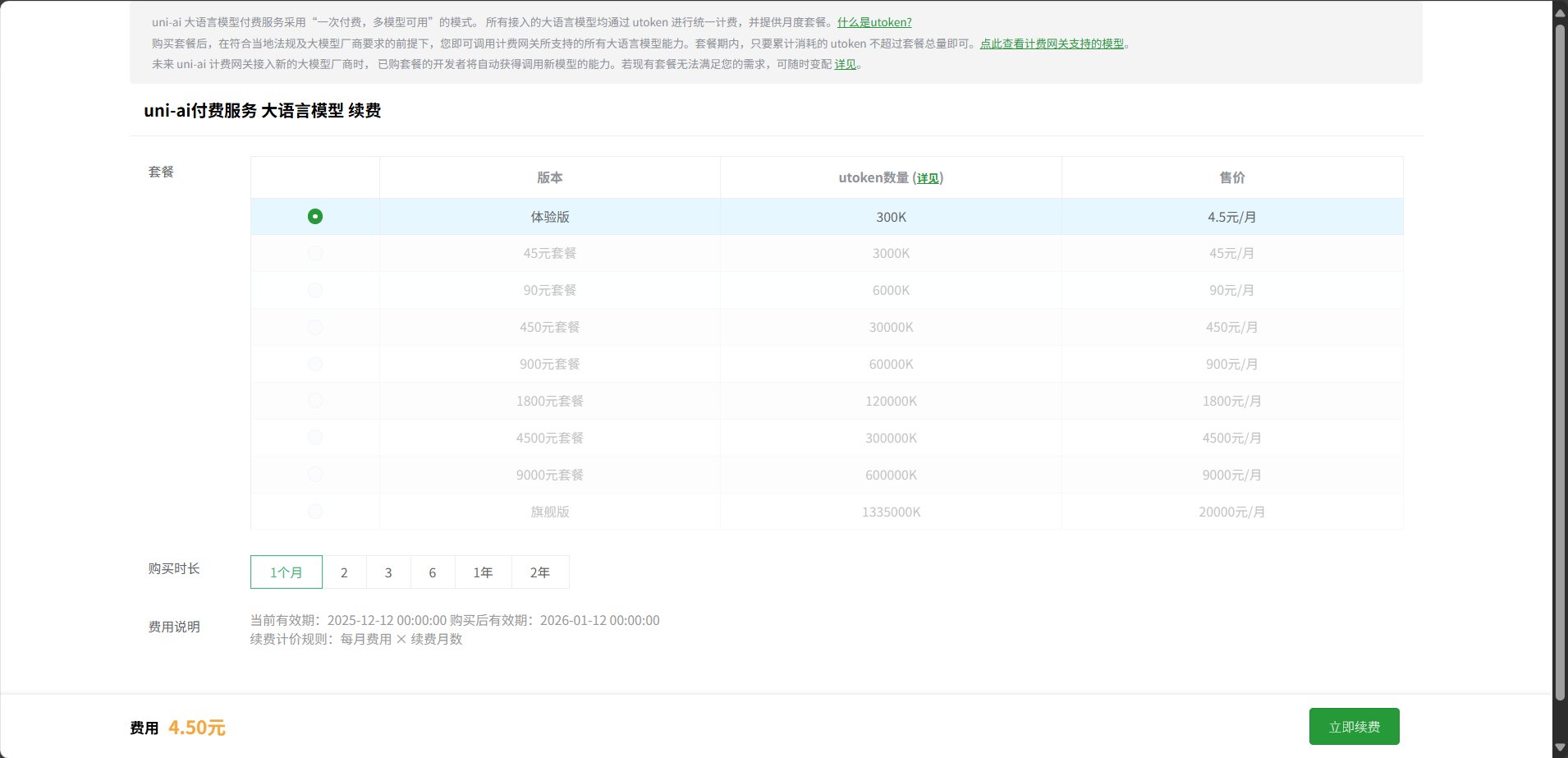
# 套餐生效中-续费
在uni-ai套餐信息页面点击续费按钮可以对套餐进行续费操作。
# 套餐生效中-升配
在uni-ai套餐信息页面点击变配按钮可以对套餐进行升配操作。升配时需要补足差价。
例:
2023年6月16日,购买2个月体验版套餐,到期时间为2023年8月16日 00:00:00,包月单价为4.5元/月。
在不同的时间点操作升配,需要支付的差价是不同的。
假如选择在第一个月2023年6月17日,将该套餐升级为45元/月的45元版套餐。则需要补差价2个月*(45-4.5)=81元
假如选择在第二个月套餐到期的前一天2023年8月15日,将该套餐升级为45元/月的45元版套餐。则需要补差价1个月*(45-4.5)=40.5元
# 套餐到期前一天-降配
在uni-ai套餐信息页面点击变配按钮可以对套餐进行降配操作。
注意
- 仅支持在套餐到期的前一天执行降配操作。
- 如果降配时token用量超过降配目标套餐的token上限,则会导致降配失败
# 套餐过期-新购
套餐到期后,套餐状态将被设置为禁用,无法再使用uni-ai相关功能。如需继续使用,您需要新购套餐。 套餐处于禁用状态后,以您执行新购操作的时间为起点计算包月时长,例如您的套餐在2023年06月10日到期,在2023年06月15日执行新购操作,购买时长为1个月,那么套餐的到期时间即为2023年7月15日。
# 计费网关支持的模型及计费标准
注意:以下所有折合价格均以4.5元体验版套餐为基准计算得出,套餐规格越高,实际折合价格越低,优惠力度越大。套餐升级说明
# 七牛云
本地运行需要HBuilderX版本 >= 4.73
| 模型名称 | 模型ID | 简介 | 用量 | 消耗 | 折合价格 |
|---|---|---|---|---|---|
| DeepSeek R1 | deepseek-r1 | DeepSeek R1 是 DeepSeek 团队发布的最新开源模型,具备非常强悍的推理性能,尤其在数学、编程和推理任务上达到了与OpenAI的o1模型相当的水平 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| DeepSeek R1 0528 | deepseek-r1-0528 | DeepSeek R1 的重大升级版本,针对复杂推理、多步骤计算更准确;长文理解与生成更连贯、逻辑更清晰;数学、编程等专业性输出更可靠。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| DeepSeek V3(默认) | deepseek-v3 | 推理速度大幅提升,位居开源模型之首,媲美顶尖闭源模型。采用负载均衡辅助策略和多标记预测训练,性能显著增强。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.534K utokens | 0.008元 | |||
| DeepSeek-V3-0324 | deepseek-v3-0324 | 推理速度大幅提升,位居开源模型之首,媲美顶尖闭源模型。采用负载均衡辅助策略和多标记预测训练,性能显著增强。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.534K utokens | 0.008元 | |||
| DeepSeek-V4-Flash | deepseek/deepseek-v4-flash | DeepSeek V4 Flash 是 DeepSeek 推出的一款经过效率优化的混合专家(Mixture-of-Experts)模型,总参数量达 2840 亿,每次前向传播激活 130 亿参数,支持长达 100 万 token 的上下文窗口。该模型专为快速推理和高吞吐量工作负载设计,同时保持了强大的推理和编程能力。模型采用混合注意力机制以实现高效的长上下文处理,并支持可配置的推理模式。它非常适用于对响应速度和成本效益要求较高的应用场景,如编程助手、聊天系统和智能体工作流。 | 1K tokens输入 | 0.067K utokens | 0.001元 |
| 1K tokens输出 | 0.134K utokens | 0.002元 | |||
| DeepSeek-V4-Pro | deepseek/deepseek-v4-pro | DeepSeek V4 Pro 是 DeepSeek 推出的大规模混合专家(Mixture-of-Experts)模型,总参数量达 1.6 万亿,每次前向传播激活 490 亿参数,支持长达 100 万 token 的上下文窗口。该模型专为高级推理、编程和长程智能体工作流设计,在知识、数学和软件工程基准测试中均表现出色。它基于与 DeepSeek V4 Flash 相同的架构,引入了混合注意力系统以实现高效的长上下文处理,并支持多种推理模式,可根据任务需求在速度和深度之间取得平衡。它非常适用于全代码库分析、多步骤自动化和大规模信息综合等复杂工作负载,这些场景对能力和效率都有极高要求。 | 1K tokens输入 | 0.8K utokens | 0.012元 |
| 1K tokens输出 | 1.6K utokens | 0.024元 | |||
| DeepSeek/DeepSeek-V3.2-Speciale | deepseek/deepseek-v3.2-speciale | V3.2-Speciale 是 DeepSeek-V3.2 的长思考增强版,同时结合了 DeepSeek-Math-V2 的定理证明能力。该模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro;它斩获 IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛)及 IOI 2025(国际信息学奥林匹克)金牌;在高度复杂任务上,Speciale 模型大幅优于标准版本,但消耗的 Tokens 也显著更多,成本更高,仅供研究使用,该版本将于北京时间 2025-12-15 23:59 停止服务。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.2K utokens | 0.003元 | |||
| Deepseek-V3.1 | deepseek-v3.1 | DeepSeek V3.1 通过显式推理(Think)、动态搜索(Search)、高效工具调用(Tool) 这三驾马车,清晰地瞄准了下一代 AI 智能体的核心能力,清晰地勾勒出一条技术演进路线:一个更自主、更可靠、更能与外部世界交互的智能体(Agent)正在成型。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 0.8K utokens | 0.012元 | |||
| Deepseek-v4-Pro-202606 | deepseek/deepseek-v4-pro-202606 | DeepSeek V4 Pro 是 DeepSeek 推出的大规模混合专家(Mixture-of-Experts)模型,总参数量达 1.6 万亿,每次前向传播激活 490 亿参数,支持长达 100 万 token 的上下文窗口。该模型专为高级推理、编程和长程智能体工作流设计,在知识、数学和软件工程基准测试中均表现出色。它基于与 DeepSeek V4 Flash 相同的架构,引入了混合注意力系统以实现高效的长上下文处理,并支持多种推理模式,可根据任务需求在速度和深度之间取得平衡。它非常适用于全代码库分析、多步骤自动化和大规模信息综合等复杂工作负载,这些场景对能力和效率都有极高要求。 | 1K tokens输入 | 0.2K utokens | 0.003元 |
| 1K tokens输出 | 0.4K utokens | 0.006元 | |||
| Deepseek/DeepSeek-V3.2 | deepseek/deepseek-v3.2-251201 | DeepSeek 发布 V3.2 正式版,显著强化了 Agent 和推理能力,在主流测试中达到 GPT-5 水平并支持思考模式下的工具调用;同时推出的 Speciale 探索版在多项国际竞赛中取得金牌级表现。模型已全面开放使用。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.2K utokens | 0.003元 | |||
| Deepseek/Deepseek V3.2 Exp | deepseek/deepseek-v3.2-exp | DeepSeek-V3.2-Exp 模型,是一个实验性(Experimental)的版本。作为迈向新一代架构的中间步骤,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.2K utokens | 0.003元 | |||
| Deepseek/Deepseek V3.2 Exp Thinking | deepseek/deepseek-v3.2-exp-thinking | DeepSeek-V3.2-Exp 模型,是一个实验性(Experimental)的版本。作为迈向新一代架构的中间步骤,V3.2-Exp 在 V3.1-Terminus 的基础上引入了 DeepSeek Sparse Attention(一种稀疏注意力机制),针对长文本的训练和推理效率进行了探索性的优化和验证。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.2K utokens | 0.003元 | |||
| Deepseek/Deepseek-Math-V2 | deepseek/deepseek-math-v2 | 大型语言模型的数学推理从追求答案正确转向确保过程严谨。研究提出“可自我验证”新范式,通过训练专门的验证器来评估证明步骤,并以此训练生成器进行自我检错。二者协同进化,推动能力边界。最终模型在IMO等顶级竞赛中达到金牌水平,展示了深度推理的巨大潜力。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| Deepseek/Deepseek-V3.1 Terminus | deepseek/deepseek-v3.1-terminus | 此次更新在保持模型原有能力的基础上,针对用户反馈的问题进行了改进,包括: 语言一致性:缓解了中英文混杂、偶发异常字符等情况; Agent 能力:进一步优化了 Code Agent 与 Search Agent 的表现。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 0.8K utokens | 0.012元 | |||
| Deepseek/Deepseek-V3.1 Terminus Thinking | deepseek/deepseek-v3.1-terminus-thinking | 此次更新在保持模型原有能力的基础上,针对用户反馈的问题进行了改进,包括: 语言一致性:缓解了中英文混杂、偶发异常字符等情况; Agent 能力:进一步优化了 Code Agent 与 Search Agent 的表现。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 0.8K utokens | 0.012元 | |||
| Doubao 1.5 Pro 32k | doubao-1.5-pro-32k | 全新升级的多模态大模型,视觉理解、分类、信息抽取等能力显著提升,并重点增强了解题、视频理解等场景的任务效果。支持 128k 上下文窗口,输出长度支持最大 16K。 | 1K tokens输入 | 0.054K utokens | 0.0008元 |
| 1K tokens输出 | 0.134K utokens | 0.002元 | |||
| Doubao 1.5 Thinking Pro | doubao-1.5-thinking-pro | 仅支持文本输入。在数学、编程、科学推理等专业领域及创意写作等通用任务中表现突出,在AIME 2024、Codeforces、GPQA等多项权威基准上达到或接近业界第一梯队水平。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| Doubao 1.5 Vision Pro | doubao-1.5-vision-pro | 全新升级的多模态大模型,视觉理解、分类、信息抽取等能力显著提升,并重点增强了解题、视频理解等场景的任务效果。支持 128k 上下文窗口,输出长度支持最大 16K。 | 1K tokens输入 | 0.2K utokens | 0.003元 |
| 1K tokens输出 | 0.6K utokens | 0.009元 | |||
| Doubao Seed 2.0 Code | doubao-seed-2.0-code | Doubao Seed 2.0 Code 面向真实编程环境优化的 Coding 模型,能稳定调用 Claude Code 等常见 IDE 中的工具。模型特别优化了前端能力,在使用常见的前端框架时能有良好表现。模型支持使用 Skills,可以配合多种自定义技能使用。 | 1K tokens输入 | 0.64K utokens | 0.0096元 |
| 1K tokens输出 | 3.2K utokens | 0.048元 | |||
| Doubao Seed 2.0 Lite | doubao-seed-2.0-lite | Doubao Seed 2.0 Lite 面向高频企业场景兼顾性能与成本的均衡型模型,综合能力超越上一代Doubao-Seed-1.8。胜任非结构化信息处理、内容创作、搜索推荐、数据分析等生产型工作,支持长上下文、多源信息融合、多步指令执行与高保真结构化输出。在保障稳定效果的同时显著优化成本。 | 1K tokens输入 | 0.121K utokens | 0.0018元 |
| 1K tokens输出 | 0.721K utokens | 0.0108元 | |||
| Doubao Seed 2.0 Min | doubao-seed-2.0-mini | Doubao Seed 2.0 Mini 面向低时延、高并发与成本敏感场景,强调快速响应与灵活推理部署。模型效果与Doubao-Seed-1.6相当。支持256k上下文、4档思考长度和多模态理解,适合成本和速度优先的轻量级任务。 | 1K tokens输入 | 0.054K utokens | 0.0008元 |
| 1K tokens输出 | 0.534K utokens | 0.008元 | |||
| Doubao Seed 2.0 Pro | doubao-seed-2.0-pro | Doubao Seed 2.0 Pro 旗舰级全能通用模型,面向 Agent 时代的复杂推理与长链路任务执行场景。强调多模态理解、长上下文推理、结构化生成与工具增强执行。复杂指令与多约束执行能力突出,可稳定应对多步复杂规划、复杂图文推理、视频内容理解与高难度分析等场景。 | 1K tokens输入 | 0.64K utokens | 0.0096元 |
| 1K tokens输出 | 3.2K utokens | 0.048元 | |||
| Doubao-Seed 1.6 | doubao-seed-1.6 | Doubao Seed 1.6全新多模态深度思考模型,同时支持auto/thinking/non-thinking三种思考模式。 non-thinking模式下,模型效果对比Doubao-1.5-pro/250115大幅提升。支持 256k 上下文窗口,输出长度支持最大 16k tokens。 | 1K tokens输入 | 0.16K utokens | 0.0024元 |
| 1K tokens输出 | 1.6K utokens | 0.024元 | |||
| Doubao-Seed 1.6 Flash | doubao-seed-1.6-flash | Doubao-Seed-1.6-flash 推理速度极致的多模态深度思考模型,TPOT低至10ms; 同时支持文本和视觉理解,文本理解能力超过上一代lite,视觉理解比肩友商pro系列模型。支持 256k 上下文窗口,输出长度支持最大 16k tokens。 | 1K tokens输入 | 0.04K utokens | 0.0006元 |
| 1K tokens输出 | 0.4K utokens | 0.006元 | |||
| Doubao-Seed 1.6 Thinking | doubao-seed-1.6-thinking | Doubao-Seed-1.6-thinking 模型思考能力大幅强化, 对比 Doubao-1.5-thinking-pro,在 Coding、Math、 逻辑推理等基础能力上进一步提升, 支持视觉理解。 支持 256k 上下文窗口 | 1K tokens输入 | 0.16K utokens | 0.0024元 |
| 1K tokens输出 | 1.6K utokens | 0.024元 | |||
| GLM-4.5 | glm-4.5 | GLM-4.5 是 GLM 系列的旗舰新模型,拥有 3550 亿个总参数和 320 亿个活动参数。作为混合推理模型,它整合了推理、编码和代理功能,提供用于复杂推理和工具运用的思维模式,以及用于即时响应的非思维模式,可满足快速发展的代理应用日益复杂的需求。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| GLM-4.5-Air | glm-4.5-air | GLM-4.5-Air 是 GLM 系列的另一款旗舰新模型,具备 1060 亿个总参数和 120 亿个活动参数。同样作为混合推理模型,它将推理、编码和代理功能统一,提供思维模式(用于复杂推理和工具运用)与非思维模式(用于即时响应),以适配代理应用的复杂需求。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.534K utokens | 0.008元 | |||
| GPT-OSS 120b | gpt-oss-120b | GPT-OSS-120b 是由 OpenAI 推出的开放权重、1170亿参数混合专家(MoE)语言模型,专为高推理能力、智能体应用及通用生产环境场景设计。该模型每次前向传播仅激活51亿参数,并通过原生 MXFP4 量化技术优化,可在单张 H100 GPU 上高效运行。该模型具备三大核心功能:可配置的推理深度、完整思维链访问机制,以及原生工具调用能力(包括函数调用、网络浏览及结构化输出生成)。 | 1K tokens输入 | 0.073K utokens | 0.00108元 |
| 1K tokens输出 | 0.361K utokens | 0.0054元 | |||
| GPT-OSS 20b | gpt-oss-20b | GPT-OSS-20b 是由 OpenAI 基于 Apache 2.0 许可证发布的开源 210 亿参数模型。该模型采用混合专家(MoE)架构,每次前向传播仅激活 36 亿参数,专为低延迟推理及消费级/单 GPU 硬件部署优化设计。模型经 OpenAI Harmony 响应格式训练,具备三大核心能力:可配置的推理等级、微调扩展性,以及包含函数调用、工具使用和结构化输出的 Agent 功能。 | 1K tokens输入 | 0.049K utokens | 0.00072元 |
| 1K tokens输出 | 0.241K utokens | 0.0036元 | |||
| Grok Code Fast 1 | x-ai/grok-code-fast-1 | Grok Code Fast 1是一款高效经济型推理模型,专为智能编码场景打造。该模型通过响应中可见的推理轨迹,让开发者能够精准引导Grok Code实现高质量的工作流程。 | 1K tokens输入 | 0.097K utokens | 0.00144元 |
| 1K tokens输出 | 0.721K utokens | 0.0108元 | |||
| Kimi K2 | kimi-k2 | Kimi K2 是一款先进的混合专家 (MoE) 语言模型,拥有 320 亿个激活参数和 1 万亿个总参数。Kimi K2 采用 Muon 优化器进行训练,在前沿知识、推理和编码任务中表现出色,同时针对代理能力进行了精心优化。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| Kimi K2 0905 | moonshotai/kimi-k2-0905 | Kimi K2 0905 是 Kimi K2 0711 的九月更新版本。该模型由月之暗面(Moonshot AI)研发,是一款大规模混合专家(MoE)语言模型,总参数量达1万亿,前向传播激活参数量为320亿。其上下文支持长度从之前的128K令牌扩展至256K令牌。 本次更新提升了智能体编程能力,在各类框架中实现更高精度和更强泛化性,并增强了前端编程表现,能够为网页、3D等任务生成更具美学价值和功能性的输出。Kimi K2 专门针对智能体能力进行优化,涵盖高级工具使用、逻辑推理和代码合成三大核心领域。其在编程(LiveCodeBench、SWE-bench)、推理(ZebraLogic、GPQA)和工具使用(Tau2、AceBench)等基准测试中表现卓越。该模型采用创新训练架构,集成MuonClip优化器以实现大规模MoE模型的稳定训练。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| Kimi K2 Thinking | moonshotai/kimi-k2-thinking | Kimi K2 Thinking 是 Moonshot AI 迄今为止最先进的开源推理模型,它将 K2 系列扩展到了智能体层面,实现了长时域推理。该模型基于 Kimi K2 中引入的万亿参数混合专家 (MoE) 架构构建,每次前向传播激活 320 亿个参数,并支持 256 个 k-token 上下文窗口。该模型针对持续的逐步思考、动态工具调用以及跨越数百轮的复杂推理工作流进行了优化。它将逐步推理与工具使用交错进行,从而能够实现自主研究、编码和写作,并能持续数百次连续操作而不会出现偏差。 它在 HLE、BrowseComp、SWE-Multilingual 和 LiveCodeBench 等开源基准测试中创造了新的纪录,同时在 200-300 次工具调用中保持了稳定的多智能体行为。基于采用 MuonClip 优化的大规模 MoE 架构,它兼具强大的推理深度和高推理效率,能够胜任高要求的智能体和分析任务。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| MiniMax-M1 | MiniMax-M1 | MiniMax-M1,世界上第一个开源的大规模混合架构的推理模型。M1在面向生产力的复杂场景中能力是开源模型中的最好一档,超过国内的闭源模型,接近海外的最领先模型,同时又有业内最高的性价比。M1有一个显著的优势是支持目前业内最高的100万上下文的输入,跟闭源模型里面的 Google Gemini 2.5 Pro 一样,是 DeepSeek R1 的 8 倍,以及业内最长的8万Token的推理输出。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 | |||
| Minimax/Minimax-M2.1 | minimax/minimax-m2.1 | MiniMax-M2.1是一款轻量级、前沿的大语言模型,针对编码、代理工作流程和现代应用开发进行了优化。仅激活了100亿个参数,它实现了在现实世界能力上的重大飞跃,同时保持了卓越的延迟、可扩展性和成本效率。 与前辈相比,M2.1提供了更干净、更简洁的输出和更快的感知响应时间。它在主要系统和应用语言中表现出领先的跨语言编码性能,在Multi-SWE-Bench上达到49.4%,在SWE-Bench Multilingual上达到72.5%,并作为IDE、编码工具和通用辅助的通用“大脑”使用。 为了避免降低该模型的表现,MiniMax强烈建议在回合之间保留推理。在我们的文档中了解更多关于使用reasoning_details传递推理的信息。 | 1K tokens输入 | 0.14K utokens | 0.0021元 |
| 1K tokens输出 | 0.56K utokens | 0.0084元 | |||
| Minimax/Minimax-M2.5 | minimax/minimax-m2.5 | Minimax M2.5专为Agent场景原生设计,编程与智能体性能(Coding & Agentic)直接对标Claude Opus 4.6,尤其在Excel高阶处理、PPT生成和深度调研等Office生产力场景达到行业领先水平(SOTA)。 | 1K tokens输入 | 0.14K utokens | 0.0021元 |
| 1K tokens输出 | 0.56K utokens | 0.0084元 | |||
| Minimax/Minimax-M2.5 Highspeed | minimax/minimax-m2.5-highspeed | Minimax M2.5 高 TPS 版本。 | 1K tokens输入 | 0.28K utokens | 0.0042元 |
| 1K tokens输出 | 1.12K utokens | 0.0168元 | |||
| Minimax/Minimax-M3 | minimax/minimax-m3 | MiniMax-M3 是 MiniMax 推出的多模态基础模型。它支持文本、图像和视频输入,输出文本,具备 100 万 token 的上下文窗口,适用于长周期智能体工作、编程和工具使用。该模型基于 MiniMax 稀疏注意力(MSA)构建,通过 KV 块选择替代全注意力机制,从而降低长上下文场景下每 token 的计算量——在处理 100 万 token 时,其成本约为上一代模型的 1/20,同时显著提升预填充和解码速度,并在大多数任务上保持质量。作为原生多模态模型,MiniMax-M3 在交错数据上进行训练,并借助交互式用户模拟器框架进行多轮、面向生产环境的协作调优。该模型面向持续性、多步骤任务,而非单轮执行。 | 1K tokens输入 | 0.56K utokens | 0.0084元 |
| 1K tokens输出 | 2.24K utokens | 0.0336元 | |||
| Moonshotai/Kimi-K2.5 | moonshotai/kimi-k2.5 | Kimi K2.5 是 Kimi 迄今最智能的模型,在 Agent、代码、视觉理解及一系列通用智能任务上取得开源 SoTA 表现。同时 Kimi K2.5 也是 Kimi 迄今最全能的模型,原生的多模态架构设计,同时支持视觉与文本输入、思考与非思考模式、对话与 Agent 任务。 | 1K tokens输入 | 0.047K utokens | 0.0007元 |
| 1K tokens输出 | 1.4K utokens | 0.021元 | |||
| Moonshotai/Kimi-K2.6 | moonshotai/kimi-k2.6 | Kimi K2.6 是 Kimi 最新最智能的模型,Kimi K2.6 的通用 Agent、代码、视觉理解等综合能力得到全面提升,其中在博士级难度的完整版人类最后的考试(Humanity’s Last Exam)、在考察模型真实软件工程能力的 SWE-Bench Pro、评估 Agent 深度检索能力的 DeepSearchQA 等基准测试中均取得行业领先的成绩,同时支持文本、图片与视频输入,思考与非思考模式,对话与 Agent 任务。 | 1K tokens输入 | 0.434K utokens | 0.0065元 |
| 1K tokens输出 | 1.8K utokens | 0.027元 | |||
| OpenAI/gpt-oss-safeguard-20b | openai/gpt-oss-safeguard-20b | gpt-oss-safeguard-20b is a safety reasoning model from OpenAI built upon gpt-oss-20b. | 1K tokens输入 | 0.037K utokens | 0.00054元 |
| 1K tokens输出 | 0.145K utokens | 0.00216元 | |||
| Qwen-Turbo | qwen-turbo | Qwen3系列Turbo模型,实现思考模式和非思考模式的有效融合,可在对话中切换模式。推理能力以更小参数规模比肩QwQ-32B、通用能力显著超过Qwen2.5-Turbo,达到同规模业界SOTA水平。 | 1K tokens输入 | 0.02K utokens | 0.0003元 |
| 1K tokens输出 | 0.04K utokens | 0.0006元 | |||
| Qwen/Qwen3.5-Plus | qwen/qwen3.5-plus | Qwen3.5原生视觉语言系列Plus模型,基于混合架构设计,融合了线性注意力机制与稀疏混合专家模型,实现了更高的推理效率。在多项任务评测中,3.5系列均展现出与当前顶尖前沿模型相媲美的卓越性能,模型效果在纯文本与多模态方面相较3系列均实现飞跃式进步。 | 1K tokens输入 | 0.267K utokens | 0.004元 |
| 1K tokens输出 | 1.6K utokens | 0.024元 | |||
| Qwen3 Max | qwen3-max | 通义千问3系列Max模型,相较preview版本在智能体编程与工具调用方向进行了专项升级。本次发布的正式版模型达到领域SOTA水平,适配场景更加复杂的智能体需求。 | 1K tokens输入 | 1K utokens | 0.015元 |
| 1K tokens输出 | 4K utokens | 0.06元 | |||
| Stepfun-Ai/Gelab Zero 4b Preview | stepfun-ai/gelab-zero-4b-preview | Gelab Zero 4b Preview 是 StepFun 推出的首款专为图形界面自动化设计的智能体模型。该模型与 GELab-Zero Agent 框架深度结合,通过自动化操作帮助用户完成各类设备交互任务。系统基于 ADB(Android 调试桥)实现对设备的精准控制,借助视觉语言模型实时理解屏幕内容,并结合智能规划模块生成操作流程并逐步执行。 | 1K tokens输入 | 0.04K utokens | 0.0006元 |
| 1K tokens输出 | 0.08K utokens | 0.0012元 | |||
| X-Ai/Grok 4 Fast | x-ai/grok-4-fast | Grok 4 Fast是xAI推出的最新多模态模型,具备SOTA级成本效益与200万token上下文窗口。 | 1K tokens输入 | 0.193K utokens | 0.00288元 |
| 1K tokens输出 | 0.481K utokens | 0.0072元 | |||
| Xiaomi/Mimo-V2-Flash | xiaomi/mimo-v2-flash | MiMo-V2-Flash 是一个专为极致推理效率自研的总参数 309B(激活 15B)的 MoE 模型,通过 Hybrid 注意力架构创新及多层 MTP 推理加速。 (2026年上线,收费版。) | 1K tokens输入 | 0.047K utokens | 0.0007元 |
| 1K tokens输出 | 0.14K utokens | 0.0021元 | |||
| Z-Ai/Autoglm Phone 9b | z-ai/autoglm-phone-9b | Autoglm Phone 是一个用于自然语言 Android 设备控制的特定领域模型,一般搭配 AutoGLM 来使用,AutoGLM 是一款手机端智能辅助框架,它能够利用 Autoglm Phone 模型以多模态的方式理解手机屏幕内容,并通过自动化操作帮助用户完成任务。系统通过 ADB(Android Debug Bridge) 来控制设备,以视觉语言模型进行屏幕能力加载,再结合智能规划生成并执行操作流程。用户只需使用自然语言描述需求,如“打开小红书搜索美食”,Phone Agent可以自动解析、了解当前界面、规划下一步动作并完成整个流程。系统还内置敏感的操作确认机制,并支持在登录或验证码场景下进行手动接管。同时,它提供远程ADB调试能力,可通过WiFi或网络连接设备,实现灵活的远程控制与开发。 | 1K tokens输入 | 0.04K utokens | 0.0006元 |
| 1K tokens输出 | 0.08K utokens | 0.0012元 | |||
| Z-Ai/GLM 4.6 | z-ai/glm-4.6 | 与GLM-4.5相比,这一代模型实现了多项关键提升: 更长的上下文窗口:上下文长度从128K令牌扩展至200K令牌,使模型能够处理更复杂的智能体任务。 卓越的编程性能:在代码基准测试中得分更高,并在Claude Code、Cline、Roo Code及Kilo Code等应用中展现出更优的实际表现,包括生成视觉效果精致的前端页面能力提升。 进阶推理能力:GLM-4.6在推理性能上取得显著进步,支持推理过程中的工具调用,综合能力进一步增强。 更强大的智能体:在工具调用和基于搜索的智能体任务中表现更出色,并能更高效地集成至智能体框架。 精细化写作:更贴合人类对文风与可读性的偏好,在角色扮演场景中的表现也更为自然流畅。 | 1K tokens输入 | 0.481K utokens | 0.0072元 |
| 1K tokens输出 | 0.84K utokens | 0.0126元 | |||
| Z-Ai/GLM 4.7 | z-ai/glm-4.7 | GLM-4.7 是智谱最新旗舰模型,GLM-4.7 面向 Agentic Coding 场景强化了编码能力、长程任务规划与工具协同,并在多个公开基准的当期榜单中取得开源模型中的领先表现。通用能力提升,回复更简洁自然,写作更具沉浸感。在执行复杂智能体任务,在工具调用时指令遵循更强,Artifacts 与 Agentic Coding 的前端美感和长程任务完成效率进一步提升。 | 1K tokens输入 | 0.212K utokens | 0.003168元 |
| 1K tokens输出 | 0.836K utokens | 0.012528元 | |||
| Z-Ai/GLM 5 | z-ai/glm-5 | GLM-5 是智谱新一代的旗舰基座模型,面向 Agentic Engineering 打造,能够在复杂系统工程与长程 Agent 任务中提供可靠生产力。在 Coding 与 Agent 能力上,GLM-5 取得开源 SOTA 表现,在真实编程场景的使用体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务,是通用 Agent 助手的理想基座。 | 1K tokens输入 | 0.4K utokens | 0.006元 |
| 1K tokens输出 | 1.467K utokens | 0.022元 | |||
| 通义千问 VL-MAX-2025-01-25 | qwen-vl-max-2025-01-25 | 在图像解析、内容识别以及视觉逻辑推导等任务中,表现出更强的准确性和细粒度分析能力。 | 1K tokens输入 | 0.2K utokens | 0.003元 |
| 1K tokens输出 | 0.6K utokens | 0.009元 | |||
| 通义千问2.5 VL 72B Instruct | qwen2.5-vl-72b-instruct | 拥有约70亿参数的多模态指令遵循大语言模型,擅长处理图像与文本信息,支持跨模态应用场景。 | 1K tokens输入 | 1.067K utokens | 0.016元 |
| 1K tokens输出 | 3.2K utokens | 0.048元 | |||
| 通义千问2.5 VL 7B Instruct | qwen2.5-vl-7b-instruct | 拥有约 70 亿参数的多模态指令遵循大语言模型,擅长处理图像与文本信息,支持跨模态应用场景。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.334K utokens | 0.005元 | |||
| 通义千问2.5-Max-2025-01-25 | qwen-max-2025-01-25 | 一个大规模 MoE 模型,已在超过 20 万亿个 token 上进行了预训练,并使用精选的监督微调 (SFT) 和从人类反馈中强化学习 (RLHF) 方法进行了进一步的后训练。 | 1K tokens输入 | 0.16K utokens | 0.0024元 |
| 1K tokens输出 | 0.64K utokens | 0.0096元 | |||
| 通义千问3 235b A22b Instruct-2507 | qwen3-235b-a22b-instruct-2507 | 基于Qwen3的非思考模式开源模型,相较上一版本(通义千问3-235B-A22B)主观创作能力与模型安全性均有小幅度提升。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.534K utokens | 0.008元 | |||
| 通义千问3 235b A22b Thinking-2507 | qwen3-235b-a22b-thinking-2507 | 基于Qwen3的思考模式开源模型,相较上一版本(通义千问3-235B-A22B)逻辑能力、通用能力、知识增强及创作能力均有大幅提升,适用于高难度强推理场景。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 1.334K utokens | 0.02元 | |||
| 通义千问3 Max Preview | qwen3-max-preview | 通义千问 3 系列 Max 模型 Preview 版本,相较 2.5 系列整体通用能力有大幅度提升。参数量达 1T,大幅减少知识幻觉,模型更智能。 | 1K tokens输入 | 1K utokens | 0.015元 |
| 1K tokens输出 | 4K utokens | 0.06元 | |||
| 通义千问3 Next 80b A3b Instruct | qwen3-next-80b-a3b-instruct | 通义千问3 Next 80B A3B Instruct是Qwen3 Next系列中经过指令微调的对话模型,专为快速稳定的响应而优化,不输出"思考"轨迹。该模型面向推理、代码生成、知识问答和多语言应用等复杂任务,同时在对齐性和格式遵循方面保持稳健性能。相较于先前Qwen3指令微调版本,该模型显著提升了超长输入和多轮对话场景下的吞吐量与稳定性,特别适合需要最终答案而非显式思维链的RAG检索增强、工具调用和智能体工作流。 | 1K tokens输入 | 0.067K utokens | 0.001元 |
| 1K tokens输出 | 0.267K utokens | 0.004元 | |||
| 通义千问3 Next 80b A3b Thinking | qwen3-next-80b-a3b-thinking | 通义千问3 Next 80B A3B Thinking是Qwen3 Next系列中优先进行推理的对话模型,默认输出结构化的"思考"轨迹。该模型专为复杂多步骤问题设计,涵盖数学证明、代码合成/调试、逻辑推理和智能体规划等领域,在知识处理、推理能力、编程辅助、对齐性及多语言评估方面表现卓越。相较于先前Qwen3版本,该模型着重提升了长链思维下的稳定性与推理时的高效扩展性,并通过调优实现了对复杂指令的精准遵循,同时减少重复或偏离任务的行为。 | 1K tokens输入 | 0.067K utokens | 0.001元 |
| 1K tokens输出 | 0.667K utokens | 0.01元 | |||
| 通义千问3-235B-A22B | qwen3-235b-a22b | Qwen3 系列的旗舰模型,在编码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等其他顶级模型相比,取得了极具竞争力的成绩。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.534K utokens | 0.008元 | |||
| 通义千问3-30B-A3B | qwen3-30b-a3b | Qwen3 系列,总参数量达 300 亿,激活参数量达 30 亿,全系列针对 MCP 调用进行了针对性的优化和增强。 | 1K tokens输入 | 0.05K utokens | 0.00075元 |
| 1K tokens输出 | 0.2K utokens | 0.003元 | |||
| 通义千问3-32B | qwen3-32b | Qwen3 系列,性能介于 Qwen3-235B-A22B 与 Qwen3-30B-A3B 之间,全系列针对 MCP 调用进行了针对性的优化和增强。 | 1K tokens输入 | 0.134K utokens | 0.002元 |
| 1K tokens输出 | 0.534K utokens | 0.008元 | |||
| 通义千问3-Coder 480b A35b Instruct | qwen3-coder-480b-a35b-instruct | Qwen3-Coder-480B-A35B-Instruct是由Qwen团队开发的混合专家(MoE)代码生成模型。该模型专为智能编码任务优化,涵盖函数调用、工具使用及代码库长上下文推理等场景。其总参数量达4800亿,每次前向传播激活350亿参数(动态激活160个专家中的8个)。 | 1K tokens输入 | 0.4K utokens | 0.006元 |
| 1K tokens输出 | 1.6K utokens | 0.024元 |
# MiniMax
| 模型 ID | 用量 | 消耗 | 折合价格 |
|---|---|---|---|
| abab6.5s-chat | 1K tokens输入 | 0.067K utokens | 0.001元 |
| 1K tokens输出 | 0.067K utokens | 0.001元 | |
abab5-chat(已下线) | 1K tokens输入 | 1K utokens | 0.015元 |
| 1K tokens输出 | 1K utokens | 0.015元 | |
abab4-chat(已下线) | 1K tokens输入 | 1K utokens | 0.015元 |
| 1K tokens输出 | 1K utokens | 0.015元 |
# Azure
| 模型 ID | 用量 | 消耗 | 折合价格 |
|---|---|---|---|
| gpt-3.5-turbo | 1K tokens输入 | 0.8K utokens | 0.012元 |
| 1K tokens输出 | 1.067K utokens | 0.016元 |
# 临时鉴权 token 方案计费说明
鉴于临时鉴权 token 方案直接请求 AI 厂商接口(绕行 DCloud 服务器),且 AI 厂商次日出具账单,因此通过计费网关调用该方案所产生的 token 消耗,将于次日下午 1 点左右完成账单结算。结算时,系统将自动将消耗量转换为 utoken,并从您的 uni-ai 套餐余量中扣除。

