
# uni-ai开发文档
# API
新增于HBuilderX正式版 3.7.10+, Alpha版 3.7.13+。
HBuilderX 3.8.5+支持在本地调试云函数时使用uni-ai计费网关
注意
使用低版本HBuilder,只能上传到uniCloud云端联调。因为低版本的uniCloud本地运行插件不支持uni-ai。云端和本地扩展库差异参考:云端和本地扩展库差异
ai作为一种云能力,相关调用被整合到uniCloud中。
如您的服务器业务不在uniCloud上,可以把云函数URL化,把uni-ai当做http接口调用。
在实际应用中,大多数场景是直接使用uni-ai-chat和uni-cms的ai功能,这些开源项目已经把完整逻辑都实现,无需自己研究API。
ai能力由uni-cloud-ai扩展库提供,在云函数或云对象中,对右键配置uni-cloud-ai扩展库。如何使用扩展库请参考:使用扩展库
如果HBuilderX版本过低,在云函数的扩展库界面里找不到uni-ai。
注意uni-ai是云函数扩展库,其api是uniCloud.ai,不是需要下载的三方插件,它是一个底层能力。
而uni-ai-chat和uni-cms等开源项目,是需要在插件市场下载的。
# 获取LLM实例
LLM,全称为Large Language Models,指大语言模型。
LLM的主要特点为输入一段前文,可以推导预测下文。
LLM不等于ai的全部,除了LLM,还有ai生成图片等其他模型。
用法:uniCloud.ai.getLLMManager(Object GetLLMManagerOptions);
注意需在相关云函数或云对象中加载uni-cloud-ai使用扩展库,否则会报找不到ai对象。
在2023年06月15日前,您不填写相关apiKey时可以免费使用uni-ai的LLM能力。但6月15日起需配置自己的apiKey或使用
uni-ai计费网关,否则无法使用。详见uni-ai计费老用户升级指南 2023年07月25日非uni-ai计费网关调用百度接口由内测接口调整为文心千帆大模型接口,HBuilderX本地调试自HBuilderX 3.8.12起支持。新接口支持流式响应。
参数说明GetLLMManagerOptions
| 参数 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
| provider | string | 否 | minimax | llm服务商,目前支持openai、baidu、minimax、azure(azure新增于HBuilderX 3.8.3)、ifly(ifly新增于HBuilderX 3.8.10)、deepseek (deepseek新增于HBuilderX 4.52)、aliyun-bailian、qiniu(aliyun-bailian、qiniu新增于HBuilderX 4.71) |
| apiKey | string | 使用uni-ai计费网关时不填。使用自己的key时必填 | - | llm服务商的apiKey。 |
| endpoint | string | 使用uni-ai计费网关时不填。使用自己的azure账户时必填 | - | azure服务端点,在azure创建ai服务时获取 |
| groupId | string | 使用uni-ai计费网关时不填。使用自己的minimax账户时必填 | - | minimax的groupId参数。 |
| accessToken | string | baidu必填 | - | llm服务商的accessToken。如何获取请参考:百度AI鉴权认证机制,需确保已开通相关接口的调用权限 (官方已不推荐使用accessToken,推荐使用apiKey方式,详见apiKey 认证鉴权) |
| proxy | string | 使用国外openai时必填,其他情况不填 | - | 可有效连接openai服务器的、可被uniCloud云函数连接的代理服务器地址。格式为IP或域名,域名不包含http前缀,协议层面仅支持https。配置为openai时必填 |
| appId | string | 使用uni-ai计费网关时,部分情况必填(见后),使用讯飞账户时必填 | - | 客户端manifest.json内的appId,部分场景下(云函数url化、定时触发)云函数/云对象无法获取客户端appId,需要通过此参数传递 |
| apiSecret | string | 讯飞必填 | - | llm服务商的apiSecret。 |
大语言模型的推理需要消耗很高的GPU算力,调用大模型需要在模型厂商处注册账户和付费。
您可以自行去大模型厂商处注册并填写相应的apiKey的参数。也可以通过DCloud来购买,即使用uni-ai计费网关。
uni-ai计费网关使用门槛低,并且可以一处充值,多模型体验。您无需在多个大模型厂商处申请,只需向DCloud购买token套餐,即可体验各种大模型的效果。
uni-ai计费网关的token计费单价与大模型厂商的定价相同,支持开具发票。
uni-ai作为一个国际化业务,支持国内外各种开发者面向国内外各种用户开发应用。 但开发者务必需注意您的应用是否符合当地政府监管要求、是否满足大模型厂商的限制政策。比如中国的大模型目前只能在大陆地区面向中国国籍用户使用,而国外的模型也有类似的区域限制。在uniCloud web控制台开通uni-ai计费网关时,您需要同意相关许可协议。
如何使用uni-ai计费网关
uni-ai计费网关目前支持付费使用七牛云提供的大模型服务和大模型厂商minimax,以及微软与openai合作提供的基于azure的ChatGPT3.5(与openai的ChatGPT3.5一致)。
计费网关支持的大模型列表详见
- 开通uni-ai付费服务:uni-ai计费网关开通流程
- 云函数中调用LLM时,不传apiKey等您向大模型厂商申请的参数
- apiKey、endpoint、groupId、accessToken等参数,是用于您自己向大模型厂商申请后填写的。如果您使用uni-ai计费网关,这些都不填且不能填。一旦您填了,就会走您自己申请的账户,而不是uni-ai计费网关。
- 目前计费网关支持的provider为:
minimax、azure、qiniu(本地运行新增于HBuilderX 4.73)。您也可以不指定,默认值为minimax。
示例
在云函数或云对象中编写如下代码调用LLM服务:
// 使用uni-ai计费网关,不指定provider,默认会走minimax
const llmManager = uniCloud.ai.getLLMManager()
// 使用uni-ai计费网关,指定provider为azure
const llmManager = uniCloud.ai.getLLMManager({
provider: 'azure'
})
// 不使用uni-ai计费网关,自行使用openai
const llmManager = uniCloud.ai.getLLMManager({
provider: 'openai',
apiKey:'your key',
proxy:'www.yourdomain.com' //也可以是ip
})
如何测试是否配置成功
在您使用uni-ai计费网关后,且在云函数代码中做好配置后。您可以:
- 运行应用,调用LLM的chatCompletion接口,看看是否返回内容
- 在uniCloud web控制台的uni-ai管理界面,查看计费报表,是否产生了对应的计费条目
appId参数说明
使用uni-ai计费网关时,在云函数url化、定时触发、云函数单实例多并发,这3个场景需要传递客户端appId,即您应用的manifest.json里的appid。
如果是在HBuilder内直接运行云函数(非客户端联调调用)也无法获取appId,此时可参考此文档进行参数模拟:模拟客户端类型
关于proxy参数的说明
云函数无法直接连通openai的服务器,您需要自行配置代理。如果使用的代理需要用户名和密码,请在代理地址中加入用户名和密码,例如:username:password@host:port。
uni-ai在请求openai时会自动将openai的域名替换为配置的代理域名或ip,一般的反向代理服务器均可满足此需求。
示例
在云函数或云对象中编写如下代码:
// 指定openai,需自行配置相关key,以及中转代理服务器
const llmManager = uniCloud.ai.getLLMManager({
provider: 'openai',
apiKey:'your key',
proxy:'www.yourdomain.com' //也可以是ip
})
# 对话
注意
对话接口响应一般比较慢,建议将云函数超时时间配置的长一些,比如30秒(客户端访问云函数最大超时时间:腾讯云为30秒,阿里云为60秒)。如何配置云函数超时时间请参考:云函数超时时间
本地运行云函数超时时间默认为10秒,超时将停止执行云函数,建议在本地调试时也将超时时间调大一些,避免调试时频繁超时。云函数本地超时时间设置
用法:llmManager.chatCompletion(Object ChatCompletionOptions)
参数说明ChatCompletionOptions
| 参数 | 类型 | 必填 | 默认值 | 说明 | 兼容性说明 |
|---|---|---|---|---|---|
| messages | array | 是 | - | 提问信息 | |
| model | string | 否 | 默认值见下方说明 | 模型名称。每个AI Provider有多个model,见下方说明 | baidu、azure(非uni-ai计费网关调用)不支持此参数 |
| deploymentId | string | 否 | - | azure模型部署id,如使用uni-ai计费网关无需传递此参数、而是要传model,详见下方说明 | 仅azure(非uni-ai计费网关调用)支持此参数 |
| number | 否 | - | 【已废弃,请使用tokensToGenerate替代】生成的token数量限制,需要注意此值和传入的messages对应的token数量相加不可大于模型最大上下文token数 | baidu不支持此参数 | |
| tokensToGenerate | number | 否 | 默认值见下方说明 | 生成的token数量限制,需要注意此值和传入的messages对应的token数量相加不可大于模型最大上下文token数 | baidu不支持此参数 |
| temperature | number | 否 | 1 | 较高的值将使输出更加随机,而较低的值将使输出更加集中和确定。建议temperature和top_p同时只调整其中一个 | baidu ERNIE-Bot-turbo不支持此参数 |
| topP | number | 否 | 1 | 采样方法,数值越小结果确定性越强;数值越大,结果越随机 | ifly、baidu ERNIE-Bot-turbo不支持此参数 |
| stream | boolean | 否 | false | 是否使用流式响应,见下方流式响应章节 | |
| sseChannel | object | 通过uni-ai计费网关使用流式响应时必填 | - | 见下方流式响应章节。客户端如何获取sseChannel对象,请参考:云函数请求中的中间状态通知通道 | |
| streamEventForSSE | string | 否 | message | 自动处理流式响应时使用的流式响应回调事件,可选:message、optimizedMessage、line。见下方流式响应章节 | |
| webSearch | boolean | 否 | false | 启用网络搜索能力,仅abab6.5s-chat(minimax)、4.0Ultra(ifly)模型支持 | 仅minimax、ifly支持此参数 |
| tools | array | 否 | - | 工具列表,用于函数调用(function calling),见下方工具调用章节, 新增于 HBuilderX 5.08 | |
| toolChoice | string/object | 否 | - | 控制模型如何选择工具,可选值:auto、none、required,或指定工具{type: "function", function: {name: "xxx"}} 新增于 HBuilderX 5.08 | |
| thinking | object | 否 | - | 思考模式开关,格式 {type: 'enabled' | 'disabled'},仅 deepseek deepseek-v4-flash、deepseek-v4-pro 模型支持,详见下方 deepseek模型说明 | 仅 deepseek 支持此参数 |
| reasoningEffort | string | 否 | - | 思考强度控制,可选值:low、medium、high、max、xhigh(其中 low、medium 会被映射为 high,xhigh 会被映射为 max),仅 deepseek deepseek-v4-flash、deepseek-v4-pro 模型支持 | 仅 deepseek 支持此参数 |
messages参数说明
需注意messages末尾有个s,它是数组,而不是简单的字符串。其中每项由消息内容content和角色role组成。
一个最简单的示例:
await llmManager.chatCompletion({
messages: [{
role: 'user',
content: '你好'
}]
})
role,即角色,有四个值:
- system 系统,对应的content一般用于对话背景设定等功能。system角色及信息如存在时只能放在messages数组第一项。ifly、baidu不支持此角色
- user 用户,对应的content为用户输入的信息
- assistant ai助手,对应的content为ai返回的信息
- tool 工具结果,用于将工具调用的执行结果返回给AI。需配合
tool_call_id字段使用,见下方工具调用章节。baidu服务商内部自动转换为function角色
message对象除了role和content外,还支持以下可选字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| role | string | 角色,必填 |
| content | string/array<object> | 消息内容,必填。文本消息使用字符串;多模态消息使用内容项数组,格式由模型决定,见下方多模态请求 |
| tool_call_id | string | 工具调用ID,当role为tool时需要传递,值为assistant消息中tool_calls返回的id |
| name | string | 工具名称,当role为tool时可传递 |
| tool_calls | array<object> | 工具调用列表,当role为assistant且AI返回了工具调用时会包含此字段,多轮工具调用时需原样传回 |
当开发者需要为用户的场景设置背景时,则需在云端代码写死system,而用户输入的问题则被放入user中,然后一起提交给LLM。
例如,提供一个法律咨询的ai咨询助手。
开发者可以在system里限制对话背景,防止ai乱答问题。然后给用户提供输入框,假使用户咨询了:“谣言传播多少人可以定罪?”,那么拼接的message就是:
const messages = [{
role: 'system',
content: '你是一名律师,回答内容仅限法律范围。'
},{
role: 'user',
content: '谣言传播多少人可以定罪?'
}]
对于不支持system的情况,如baidu,只能把system对应的内容写到第一条user信息内,也可以达到一定范围内的控制效果。
注意:对于法律、医学等专业领域需要准确回答的,建议使用gpt-4模型。其他模型更适合闲聊、文章内容生成。
assistant这个角色的内容,是ai返回的。当需要持续聊天、记忆前文时,需使用此角色。
因为LLM没有记忆能力,messages参数内需要包含前文,LLM才能记得之前聊天的内容。
以下的messages示例,是第二轮ai对话时发送的messages的示例。在这个示例中,第一个user和assistant的内容,是第一轮ai对话的聊天记录。 最后一个user是第二轮对话时用户提的问题。
因为用户提问的内容“从上述方法名中筛选首字母为元音字母的方法名”,其中有代词“上述”,为了让ai知道“上述”是什么,需要把第一轮的对话内容也提交。
const messages = [{
role: 'system',
content: '以下对话只需给出结果,不要对结果进行解释。'
},{
role: 'user',
content: '以数组形式返回nodejs os模块的方法列表,数组的每一项是一个方法名。'
}, {
role: 'assistant',
content: '以下是 Node.js 的 os 模块的方法列表,以数组形式返回,每一项是一个方法名:["arch","cpus","endianness","freemem","getPriority","homedir","hostname","loadavg","networkInterfaces","platform","release","setPriority","tmpdir","totalmem","type","uptime","userInfo"]'
}, {
role: 'user',
content: '从上述方法名中筛选首字母为元音字母的方法名,以数组形式返回'
}]
在持续对话中需注意,messages内容越多则消耗的token越多,而LLM都是以token计费的。
token是LLM的术语,ai认知的语言是经过转换的,对于英语,1个token平均是4个字符,大约0.75个单词;对于中文,1个汉字大约是2个token。
如何在节省token和保持持续对话的记忆之间平衡,是一个挺复杂的事情。开发者需在适合时机要求ai对上文进行总结压缩,下次对话传递总结及总结之后的对话内容以实现更长的对话。
DCloud在uni-ai-chat和uni-cms中, 已经写好了这些复杂逻辑。开发者直接使用DCloud封装好的开源项目模板即可。
在上述例子中,还可以看到一种有趣的用法,即要求ai以数组方式回答问题。这将有利于开发者格式化数据,并进行后置增强处理。
model参数说明 @model
每个AI Provider可以有多个model,比如对于openai,ChatGPT的模型是gpt-3.5-turbo,而gpt-4的模型就是gpt-4。不同模型的功能、性能、价格都不一样。
也有一些AI Provider只有一个模型,此时model参数可不填。
如果您需要非常精准的问答,且不在乎成本,推荐使用gpt-4。如果是普通的文章内容生成、续写,大多数模型均可胜任。
| 服务商 | 接口 | 模型 |
|---|---|---|
| qiniu | chatCompletion | 常用热门大模型 通义千问:qwen3-max、qwen3-max-preview、qwen3-32b、qwen-turbo 等 deepseek:deepseek-v3.1、deepseek-v3(默认值)、deepseek-r1、deepseek/deepseek-v3.2-251201、deepseek/deepseek-v3.2-speciale 等 豆包:doubao-1.5-pro-32k、doubao-1.5-thinking-pro、doubao-seed-1.6-thinking 等 Kimi:kimi-k2、moonshotai/kimi-k2-0905、moonshotai/kimi-k2-thinking 等 更多大模型详见七牛云模型广场 模型ID详见各个大模型详情中的Model ID 计费网关可用模型详见七牛云计费网关模型列表 |
| openai | chatCompletion | gpt-4、gpt-4-0314、gpt-4-32k、gpt-4-32k-0314、gpt-3.5-turbo(默认值)、gpt-3.5-turbo-0301 |
| minimax | chatCompletion | abab4-chat、abab5-chat(默认值)、abab6.5s-chat |
| azure(通过uni-ai计费网关调用) | chatCompletion | gpt-3.5-turbo(默认值) |
| baidu(文心千帆) | chatCompletion | accessToken 认证鉴权:ERNIE-Bot(默认值)、ERNIE-Bot-turbo apiKey 认证鉴权:支持百度千帆模型广场所有模型,模型ID详见模型详情中的接入点ID |
| ifly | chatCompletion | lite(默认值)、generalv3、pro-128k、generalv3.5、max-32k、4.0Ultra |
| deepseek | chatCompletion | deepseek-v4-flash(默认值)、deepseek-v4-pro、deepseek-chat(将于 2026/07/24 弃用)、deepseek-reasoner(将于 2026/07/24 弃用) |
| aliyun-bailian | chatCompletion | 支持阿里云百炼模型广场所有模型,模型ID详见各个大模型详情中的模型Code |
模型最大上下文token数、字数限制
openai gpt-3.5-turbo: 4097
azure gpt-3.5-turbo: 8192
abab4-chat、abab5-chat: 4096
deepseek-v4-flash、deepseek-v4-pro: 1M
deepseek-chat、deepseek-reasoner: 8192
baidu文心千帆最后一个message的content长度(即此轮对话的问题)不能超过2000个字符;如果messages中content总长度大于2000字符,系统会依次遗忘最早的历史会话,直到content的总长度不超过2000个字符
tokensToGenerate参数说明
tokensToGenerate指生成的token数量限制,即返回的文本对应的token数量不能超过此值。注意这个值不是总token。
注意此值和传入messages对应的token数量,两者相加不可大于模型最大上下文token数。如果messages对应的token数为1024,当传递的tokensToGenerate参数大于(模型最大上下文token数-1024)时接口会抛出错误。
使用minimax时默认最多生成512个token的结果,也就是返回结果不会很长。如有需求请自行调整此值。
deploymentId参数说明
自行设置apikey调用azure接口时需要传deploymentId,使用uni-ai计费网关访问azure服务时需要传递model而不是deploymentId。目前通过uni-ai计费网关调用azure接口仅支持gpt-3.5-turbo这一个模型。
deepseek模型说明
deepseek-v4-flash、deepseek-v4-pro 是 deepseek 升级后的模型,均支持思考模式:在输出最终回答之前,模型会先输出一段思维链内容,以提升最终答案的准确性。可通过 thinking 参数控制思考模式开关(默认 enabled),通过 reasoningEffort 参数控制思考强度。
deepseek-chat、deepseek-reasoner 模型名将于 2026/07/24 弃用。出于兼容考虑,二者分别对应 deepseek-v4-flash 的非思考与思考模式,调用时 uni-ai 会自动转换为 deepseek-v4-flash 并设置对应的 thinking 参数,业务代码无需感知此变化。
deepseek-reasoner(即 deepseek-v4-flash 的思考模式)模型在正式回答之前会生成思考过程,用于推理、解释、问答等场景。
deepseek 思考模式下的输出 token 数包含了思维链和最终答案的所有 token。
chatCompletion方法的返回值
| 参数 | 类型 | 必备 | 默认值 | 说明 | 兼容性说明 |
|---|---|---|---|---|---|
| id | string | openai必备 | - | 本次回复的id | 仅openai返回此项 |
| reply | string | 是 | - | ai对本次消息的回复 | |
| toolCalls | array<object> | 否 | - | AI返回的工具调用列表,见下方工具调用章节 | |
| |--id | string | 否 | - | 工具调用ID,多轮工具调用时需传回此值 | |
| |--type | string | 否 | - | 工具类型,固定值function | |
| |--function | object | 否 | - | 工具调用的函数信息 | |
| |--name | string | 否 | - | 函数名称 | |
| |--arguments | string | 否 | - | 函数参数,JSON字符串格式 | |
| annotations | array<object> | 否 | - | 启用网络搜索后本次消息中出现的内容引用注解 | 仅minimax返回 |
| |--text | string | 否 | - | 注解名称;用于匹配消息中的注解占位字符串 | 仅minimax返回 |
| |--url | string | 否 | - | 引用内容地址 | 仅minimax返回 |
| |--quote | string | 否 | - | 引用内容摘要 | 仅minimax返回 |
| choices | array<object> | 否 | - | 所有生成结果 | 百度不返回此项 |
| |--finishReason | string | 否 | - | 截断原因,stop(正常结束)、length(超出maxTokens被截断)、tool_calls(需要调用工具) | |
| |--message | object | 否 | - | 返回消息 | |
| |--role | string | 否 | - | 角色 | |
| |--content | string | 否 | - | 消息内容 | |
| |--reasoningContent | string | 否 | - | 仅适用于 deepseek 思考模式(deepseek-v4-flash、deepseek-v4-pro 及已弃用的 deepseek-reasoner)。内容为 assistant 消息中在最终答案之前的推理内容 | |
| |--annotations | array<object> | 否 | - | 启用网络搜索后本次消息中出现的内容引用注解 | 仅minimax返回 |
| |--text | string | 否 | - | 注解名称;用于匹配消息中的注解占位字符串 | 仅minimax返回 |
| |--url | string | 否 | - | 引用内容地址 | 仅minimax返回 |
| |--quote | string | 否 | - | 引用内容摘要 | 仅minimax返回 |
| usage | object | 是 | - | 本次对话token消耗详情 | |
| |--promptTokens | number | 否 | - | 输入的token数量 | minimax返回undefined |
| |--completionTokens | number | 否 | - | 生成的token数量 | minimax返回undefined |
| |--totalTokens | number | 是 | - | 总token数量 | |
| |--reasoningTokens | number | 否 | - | 仅适用于 deepseek 思考模式(deepseek-v4-flash、deepseek-v4-pro 及已弃用的 deepseek-reasoner)。推理模型所产生的思维链 token 数量 |
# 简单示例
在你的云函数中加载uni-cloud-ai扩展库,写下如下代码,ctrl+r运行,即可调用ai返回结果。
const llmManager = uniCloud.ai.getLLMManager({
provider: 'azure'
})
const res = await llmManager.chatCompletion({
messages: [{
role: 'user',
content: 'uni-app是什么,20个字以内进行说明'
}]
})
console.log(res);
如果你之前未使用过uniCloud,后续有专门的新手指南章节。
# 流式响应
新增于HBuilderX正式版 3.7.10+, alpha版 HBuilderX 3.8.0+。
uni-ai chatCompletion接口支持传sseChannel参数的用法云端支持新增于2023年6月15日,HBuilderX 3.8.5+支持在本地调试云函数时使用此用法。使用uni-ai计费网关流式响应时,sseChannel参数必填
访问AI聊天接口时,如生成内容过大,响应时间会很久,前端用户需要等待很长时间才会收到结果。
实际上AI是逐渐生成下一个token的,所以可使用流式响应,类似不停打字的打字机那样,让前端用户陆续看到AI生成的内容。
以往云函数只有return的时候,才能给客户端返回消息。在流式响应中,需要云函数支持sse,在return前给客户端一直发送通知。
uniCloud的云函数,基于uni-push2提供了sse通道,即云函数请求中的中间状态通知通道。
在调用chatCompletion接口时传递参数stream: true即可开启流式响应。使用uni-ai计费网关时还需要传递sseChannel才可以使用流式响应。
关于使用uni-ai计费网关时使用流式响应的说明
流式响应需要云端持续从服务商接收数据并发送给客户端,这需要云函数一直保持运行(云函数无法一直保持运行,详情参考:超时时间)。如果使用uni-ai计费网关则无需云函数保持运行,在请求发送给DCloud服务器后DCloud服务器会使用推送通道将结果通知给客户端,而云函数可以再继续处理下一个请求或者直接休眠,从而节省大量云函数资源(GBs)。
注意:
- 需提前为应用开通uni-push2
- 不同provider的流式支持度不同,有的message事件是按字输出、有的是按句输出。
- 开启流式响应后
chatCompletion接口将返回流对象,而不会返回具体结果。开发者需要使用流获取AI响应的内容。 chatCompletion接口传sseChannel参数时,chatCompletion接口不会返回流对象,只会返回{errCode: 0}。- 如使用nginx代理,需要将代理配置为
proxy_buffering off;,否则可能会遇到Unexpected end of JSON input错误
stream对象有七个事件:
- message: 收到AI响应的事件,回调函数内可以获取AI返回的信息。需要注意的是在使用不同服务商时message事件的响应可能有些不同,有些服务商是一个字一个字的返回,有些则是一段一段的返回。
- optimizedMessage: 收到AI响应的事件,基于message事件降频得到,使用此事件可以避免非常频繁的往客户端发送请求,导致部分情况下客户端处理消息卡顿。云端新增于
2023年6月21日,HBuilderX本地调试将于下次发版支持。 - line: AI响应一行文字时触发,回调函数内可以获取这行文字的内容。uni-ai对服务商返回内容做了处理,AI每响应一个段落会触发一次此事件
- end: AI响应完毕事件
- error: AI响应错误事件,回调函数内可以获取具体错误信息
- messageAnnotations: 启用网络搜索后本次消息中出现的内容引用注解事件,回调函数内可以获取引用内容的注解信息,HBuilderX本地调试新增于
4.51版本 - reasoningMessage: 仅适用于 deepseek 思考模式(deepseek-v4-flash、deepseek-v4-pro 及已弃用的 deepseek-reasoner)。回调函数内可获取思维链内容。HBuilderX本地调试新增于
4.52版本。 - optimizedReasoningMessage: 仅适用于 deepseek 思考模式(deepseek-v4-flash、deepseek-v4-pro 及已弃用的 deepseek-reasoner)。回调函数内可获取思维链内容,基于message事件降频得到,使用此事件可以避免非常频繁的往客户端发送请求,导致部分情况下客户端处理消息卡顿。HBuilderX本地调试新增于
4.52版本。 - toolCalls: AI返回工具调用时触发,回调函数内可获取完整的工具调用列表(数组)。此事件在end事件之前触发。仅在传入了tools参数且AI决定调用工具时才会触发。
注意,以上事件属于stream对象,不要和sseChannel的事件搞混了,云端调用sseChannel.write客户端就需要使用sseChannel.on('message')进行接受,例如sseChannel并没有optimizedMessage事件。
云函数代码示例
// 将sseChannel传递给chatCompletion接口,由uni-ai自动往客户端发送流式响应
'use strict';
exports.main = async (event, context) => {
const llmManager = uniCloud.ai.getLLMManager({
provider: 'azure'
})
const res = await llmManager.chatCompletion({
messages: [{
role: 'user',
content: '介绍一下uni-app,400字以内,分为两段'
}],
tokensToGenerate: 400,
stream: true, // 开启流式返回
sseChannel: event.channel
})
return {
errCode: 0,
errMsg: ''
}
};
// 自行处理流式响应,上述将sseChannel传递给chatCompletion接口的等价写法
'use strict';
exports.main = async (event, context) => {
const sseChannel = uniCloud.deserializeSSEChannel(event.channel)
const llmManager = uniCloud.ai.getLLMManager({
provider: 'azure'
})
let streamRes
try {
streamRes = await llmManager.chatCompletion({
messages: [{
role: 'user',
content: '介绍一下uni-app,400字以内,分为两段'
}],
tokensToGenerate: 400,
stream: true // 开启流式返回
})
} catch (e) {
console.error(e)
throw e
}
return new Promise((resolve, reject) => { //流式给客户端返回数据
streamRes.on('line', (line) => {
console.log('---line----', line) // 返回一行时触发,即\n
})
// streamRes.on('message', async (message) => { // 部分服务商message事件频率过高可能导致客户端卡顿,建议使用optimizedMessage事件
// await sseChannel.write(message)
// console.log('---message----', message) // 实时触发
// })
streamRes.on('optimizedMessage', async (message) => { // optimizedMessage事件
await sseChannel.write(message)
console.log('---message----', message) // 实时触发
})
streamRes.on('messageAnnotations', async (annotations) => { // messageAnnotations事件
console.log('---annotations----', annotations) // 实时触发
})
streamRes.on('end', async () => {
console.log('---end----') // 响应结束
await sseChannel.end({
errCode: 0,
errMsg: ''
})
resolve({
errCode: 0,
errMsg: ''
})
})
streamRes.on('error', (err) => {
await sseChannel.end({
errCode: err.errCode || err.code,
errMsg: err.errMsg || err.message,
})
console.log('---error----', err)
reject(err)
})
})
};
客户端也需要接收云函数的流式响应。
DCloud提供了开源的uni-ai-chat,对流式响应进行了前后端一体的封装,使用更简单,参考:uni-ai-chat
# 多模态请求
多模态模型可以同时接收文本、图片、视频或音频等内容。请求多模态模型时,messages的用法不变,但对应消息的content通常需要从字符串改为内容项数组。
注意
多模态参数没有适用于所有模型的统一格式。不同服务商、不同模型支持的模态以及content内容项的字段、嵌套结构、文件格式、文件大小限制都可能不同。切换模型时不能只替换model,还需要按照该模型的文档调整多模态参数。
下面以uni-ai计费网关中的七牛云qwen2.5-vl-7b-instruct模型为例,按照OpenAI兼容格式请求模型理解一张图片:
const llmManager = uniCloud.ai.getLLMManager({
provider: 'qiniu'
})
const res = await llmManager.chatCompletion({
model: 'qwen2.5-vl-7b-instruct',
messages: [{
role: 'user',
content: [{
type: 'text',
text: '请描述图片中的主要内容'
}, {
type: 'image_url',
image_url: {
url: 'https://example.com/image.jpg'
}
}]
}]
})
console.log(res.reply)
同一条消息需要传入多张图片时,可以增加多个image_url内容项:
const imageUrls = [
'https://example.com/image-1.jpg',
'https://example.com/image-2.jpg'
]
const res = await llmManager.chatCompletion({
model: 'qwen2.5-vl-7b-instruct',
messages: [{
role: 'user',
content: [{
type: 'text',
text: '比较这两张图片的不同之处'
}, ...imageUrls.map(url => ({
type: 'image_url',
image_url: { url }
}))]
}]
})
使用其他模型前,请重点核对以下差异:
| 核对项 | 常见差异 |
|---|---|
| 模型能力 | 有些模型只支持文本,有些支持图片,只有部分模型支持视频或音频 |
| 内容项字段 | 图片可能使用image_url或image,视频和音频通常使用各自的专用字段 |
| 字段结构 | 资源地址可能是字符串,也可能是包含url等参数的对象 |
| 资源传递方式 | 部分模型只支持公网URL,部分模型还支持Base64或Data URL |
| 附加参数 | 图片清晰度、视频抽帧频率、音频格式等参数及取值范围可能不同 |
示例中的图片URL必须能被模型服务商直接访问,不能使用本地文件路径。是否支持Base64、临时URL以及URL对应的文件格式和大小,请以实际模型文档为准。多模态内容也会计入模型输入token或其他计费项,具体计费规则参考计费网关支持的模型及计费标准。
# 工具调用(Function Calling)
工具调用允许你定义一组工具(函数),AI模型可以根据用户的问题判断是否需要调用这些工具,并返回工具调用的参数。开发者执行工具后,将结果返回给AI,AI再基于工具结果生成最终回答。
支持的服务商
| 服务商 | 支持情况 | 说明 |
|---|---|---|
| openai | ✓ | 完整支持 |
| azure | ✓ | 完整支持 |
| deepseek | ✓ | 完整支持 |
| aliyun-bailian | ✓ | 完整支持(通过OpenAI兼容接口) |
| qiniu | ✓ | 完整支持(通过OpenAI兼容接口) |
| minimax | ✓ | V2及以上模型支持 |
| baidu | ✓ | 支持(内部自动转换为ERNIE的functions格式) |
| ifly | ✓ | 完整支持(通过OpenAI兼容HTTP接口) |
| dcloud | ✓ | 通过计费网关透传tools参数 |
tools参数说明
tools是一个数组,每项定义一个工具:
const tools = [
{
type: 'function',
function: {
name: 'get_weather', // 函数名称
description: '获取指定城市的天气信息', // 函数描述,帮助AI判断何时调用
parameters: { // 函数参数,JSON Schema格式
type: 'object',
properties: {
city: {
type: 'string',
description: '城市名称,例如:北京'
}
},
required: ['city']
}
}
}
]
toolChoice参数说明
| 值 | 说明 |
|---|---|
| auto | AI自行决定是否调用工具(默认行为) |
| none | 强制AI不调用任何工具 |
| required | 强制AI必须调用工具 |
{type: "function", function: {name: "xxx"}} | 强制AI调用指定名称的工具 |
非流式工具调用示例
// 第一步:定义工具并发起对话
const llmManager = uniCloud.ai.getLLMManager({
provider: 'openai',
apiKey: 'your key',
proxy: 'www.yourdomain.com'
})
const tools = [{
type: 'function',
function: {
name: 'get_weather',
description: '获取指定城市的天气信息',
parameters: {
type: 'object',
properties: {
city: { type: 'string', description: '城市名称' }
},
required: ['city']
}
}
}]
const res = await llmManager.chatCompletion({
messages: [{ role: 'user', content: '北京今天天气怎么样?' }],
tools
})
// 第二步:检查AI是否返回了工具调用
if (res.toolCalls && res.toolCalls.length > 0) {
const toolCall = res.toolCalls[0]
const args = JSON.parse(toolCall.function.arguments)
// 第三步:执行工具函数(开发者自行实现)
const weatherResult = await getWeather(args.city) // 例如返回 "晴,25°C"
// 第四步:将工具结果返回给AI,获取最终回答
const finalRes = await llmManager.chatCompletion({
messages: [
{ role: 'user', content: '北京今天天气怎么样?' },
{ role: 'assistant', content: '', tool_calls: res.toolCalls }, // 原样传回assistant的tool_calls
{ role: 'tool', tool_call_id: toolCall.id, content: weatherResult } // 工具执行结果
],
tools
})
console.log(finalRes.reply) // AI基于天气数据生成的自然语言回答
}
流式工具调用示例
const streamRes = await llmManager.chatCompletion({
messages: [{ role: 'user', content: '北京今天天气怎么样?' }],
tools,
stream: true
})
streamRes.on('toolCalls', (toolCalls) => {
// toolCalls为完整的工具调用数组,在end事件之前触发
console.log('AI需要调用工具:', toolCalls)
// 后续处理同非流式示例的第三、四步
})
streamRes.on('message', (msg) => {
// 如果AI不需要调用工具,会直接返回文本消息
console.log(msg)
})
streamRes.on('end', () => {
console.log('响应结束')
})
注意事项
- 当AI决定调用工具时,
reply可能为空字符串,finishReason为tool_calls - 工具调用的参数(
toolCalls[].function.arguments)是JSON字符串,需要使用JSON.parse()解析 - 多轮工具调用时,需要在messages中按顺序包含:用户消息 → assistant消息(含tool_calls)→ tool消息(含执行结果),然后再次调用chatCompletion
- baidu服务商内部会自动将tools格式转换为ERNIE的functions格式,tool角色的消息会自动转换为function角色
# AI多媒体能力
新增于HBuilderX 3.8.2
# 创建AI多媒体实例
包含AI生成图片等多媒体处理能力
用法:uniCloud.ai.getMediaManager(Object GetMediaManagerOptions);
注意需在相关云函数或云对象中加载uni-cloud-ai使用扩展库,否则会报找不到ai对象。
参数说明GetMediaManagerOptions
| 参数 | 类型 | 必填 | 默认值 | 说明 |
|---|---|---|---|---|
| provider | string | 否 | - | 服务商,目前仅支持baidu。 |
| accessToken | string | 否 | - | llm服务商的accessToken。目前百度是必填,如何获取请参考:百度AI鉴权认证机制 |
示例
在云函数或云对象中编写如下代码:
const mediaManager = uniCloud.ai.getMediaManager({
provider: 'baidu',
accessToken:'your baidu access token'
})
# 创建图片生成任务
用法:mediaManager.imageGeneration(Object ImageGenerationOptions)
参数说明ImageGenerationOptions
| 参数 | 类型 | 必填 | 默认值 | 说明 | 兼容性说明 |
|---|---|---|---|---|---|
| version | number | 否 | 1(百度) | 接口版本 | |
| prompt | string | 是 | - | 图片生成所用的提示词 | |
| resolution | string | 否 | 1024*1024 | 图片分辨率,详见下方说明 | |
| imageNum | number | 否 | - | 生成图片数量 | |
| prompt | string | 是 | - | 提问信息 | |
| style | string | 百度v1接口必填 | - | 图片风格,详见下方说明 | 仅百度v1接口支持 |
| imageBase64 | string | 否 | - | 参考图base64,仅能指定一个参考文件 | 仅百度v2接口支持 |
| imageUrl | string | 否 | - | 参考图url,仅能指定一个参考文件 | 仅百度v2接口支持 |
| pdfBase64 | string | 否 | - | 参考pdf文件base64,仅能指定一个参考文件 | 仅百度v2接口支持 |
| pdfPageNum | number | 否 | 1 | 参考pdf文件页码 | 仅百度v2接口支持 |
| changeDegree | number | 否 | - | 参考图影响因子,支持 1-10 ;数值越大参考图影响越大 | 仅百度v2接口支持 |
style参数说明
百度v1接口(AI作画-基础版)支持的风格:探索无限、古风、二次元、写实风格、浮世绘、low poly 、未来主义、像素风格、概念艺术、赛博朋克、洛丽塔风格、巴洛克风格、超现实主义、水彩画、蒸汽波艺术、油画、卡通画
百度v2接口(AI作画-高级版)不支持传风格,如需指定风格可尝试在提示词内指定
resolution参数说明
百度v1接口支持以下分辨率:10241024、10241536、1536*1024
百度v2接口支持以下分辨率:512512、640360、360640、10241024、7201280、1280720
返回值
| 参数 | 类型 | 必备 | 说明 | 兼容性说明 |
|---|---|---|---|---|
| taskId | number | 是 | 创建的图片生成任务的id,用于查询任务状态及获取结果 |
示例
在云函数或云对象中编写如下代码:
const res = await mediaManager.imageGeneration({
version: 1,
prompt: '睡莲',
style: '赛博朋克'
})
const taskId = res.taskId
# 获取图片生成结果
用法:mediaManager.getGeneratedImage(Object GetGeneratedImageOptions)
参数说明GetGeneratedImageOptions
| 参数 | 类型 | 必填 | 默认值 | 说明 | 兼容性说明 |
|---|---|---|---|---|---|
| version | number | 否 | 1(百度) | 接口版本 | |
| taskId | number | 是 | - | 创建任务接口返回的taskId |
返回值
| 字段 | 类型 | 必备 | 说明 | 兼容性说明 |
|---|---|---|---|---|
| status | string | 是 | 任务状态 | 见下方说明 |
| imgList | array<object> | 否 | 生成的图片列表 | |
| |--url | string | 否 | 生成的图片url | |
| |--securityCheckResult | array | 否 | 图片审核状态 | 仅百度v2接口支持 |
参数status说明
百度v1接口支持的状态为:'RUNNING'(任务执行中)、'SUCCESS'(任务成功);
百度v2接口支持的状态为:'INIT'(任务创建中)、'WAIT'(任务等待中)、'RUNNING'(任务执行中)、'FAILED'(任务失败)、'SUCCESS'(任务成功);
参数securityCheckResult说明
审核状态有以下几种: 'block'(违规)、'review'(需要人工核查)、'pass'(通过审核)
示例
在云函数或云对象中编写如下代码:
const res = await mediaManager.getGeneratedImage({
version: 1,
taskId: 123456,
})
# 获取临时鉴权 token
新增于HBuilderX 4.71,计费网关(七牛云)新增于HBuilderX 4.75
为了保证在前端调用大模型时不暴露服务商的apiKey信息,uni-ai提供了获取临时鉴权 token 接口。 前端调用此接口获取临时 token 后,使用临时 token 调用服务商的api。
通过使用临时鉴权 token,可以避免在流式返回过程中云函数持续运行带来的资源消耗,将请求直接转发到服务商,大大降低云函数的运行成本。
注意
此接口目前仅支持阿里云百炼、计费网关(七牛云)
使用场景与优势
- 降低费用成本: 流式返回时,如果直接通过云函数调用,云函数需要持续运行直到完成返回,消耗大量GBs资源。使用临时token后,前端可以直接调用服务商API,避免云函数长时间运行。
- 提高响应效率: 减少了云函数作为中间层的处理时间,响应更加迅速。
- 保障安全性: 避免在前端暴露真实的apiKey,临时token具有时效性(60秒),安全性更高。
用法:llmManager.getTempToken()
getToken方法返回值
| 参数 | 类型 | 必备 | 默认值 | 说明 | 兼容性说明 |
|---|---|---|---|---|---|
| token | string | 是 | - | 临时鉴权 token,有效期为 60 秒 | 仅阿里云百炼、计费网关(七牛云)支持 |
| expiresAt | number | 是 | - | token过期时间,单位为毫秒 | 仅阿里云百炼、计费网关(七牛云)支持 |
示例
云函数(getToken)
exports.main = function getToken () {
const llmManager = uniCloud.ai.getLLMManager({
provider: 'aliyun-bailian',
apiKey: '', // 此 apiKey 为阿里云百炼控制台创建的 apiKey,如使用计费网关(七牛云)则不需要传递此参数
})
return llmManager.getTempToken()
}
uniapp 客户端
const res = await uniCloud.callFunction({
name: 'getToken'
})
const {token: apiKey} = res.result
// 请求服务商的api, 以阿里云百炼为例
const requestTask = uni.request({
url: 'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions',
header: {
Authorization: `Bearer ${apiKey}`,
},
data: {
model: 'qwen3-32b',
messages: [
{
role: 'user',
content: '你好?'
}
]
},
dataType: "json",
success(res) {
console.log(res.data)
},
fail(err) {
reject(err)
}
})
# 错误码
在调用uni-cloud-ai提供的api时,如果出现错误,接口会将错误对象抛出。如需处理此类错误需对错误进行捕获
捕获错误的代码示例
try {
await llmManager.chatCompletion({
messages: [{
role: 'user',
content: '你好'
}]
})
} catch (e) {
console.log(e.errCode, e.errMsg)
// TODO 处理错误
}
完整错误码列表如下
| 错误码 | 错误描述 |
|---|---|
| 50001 | 缺少参数 |
| 50002 | 参数错误 |
| 60000 | 请求服务商接口时遇到网络错误 |
| 60001 | 服务商接口抛出的错误 |
| 60002 | 接口调用凭证、key等信息有误 |
| 60003 | 触发了服务商限流策略 |
| 60004 | 服务商检测到AI输出了敏感内容 |
常见错误信息
错误码:60000,错误信息:"A network error occurred while requesting xxx"
请求服务商接口时遇到网络错误,如果是请求openai接口请注意需要使用代理,如果使用了代理仍遇到此错误,请检查代理连通性是否有问题
错误信息:"certificate has expired"
# 费用
- 如果您自己去ai厂商申请和缴费,比如openai,则缴费后在uni-ai中配置相关key即可使用。
- 如果您使用uni-ai付费服务,详见。
# 初次使用uniCloud用户指南
如之前未使用过uni-app,那请重头学起。uni-app官网
如了解uni-app,但未使用过uniCloud。请参考本章节继续。
首先注册开通uniCloud,登录https://unicloud.dcloud.net.cn/,创建一个服务空间。
在uni-app项目点右键创建uniCloud环境,关联之前创建的服务空间。
创建uniCloud云函数
在项目下uniCloud目录右键,新建云函数
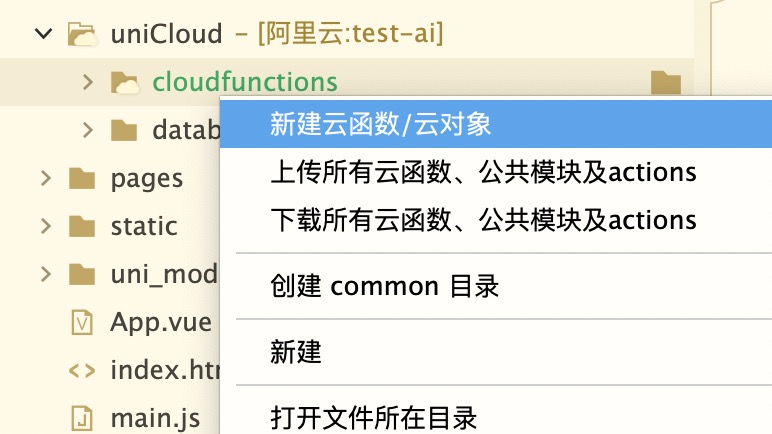
填写云函数名称,比如
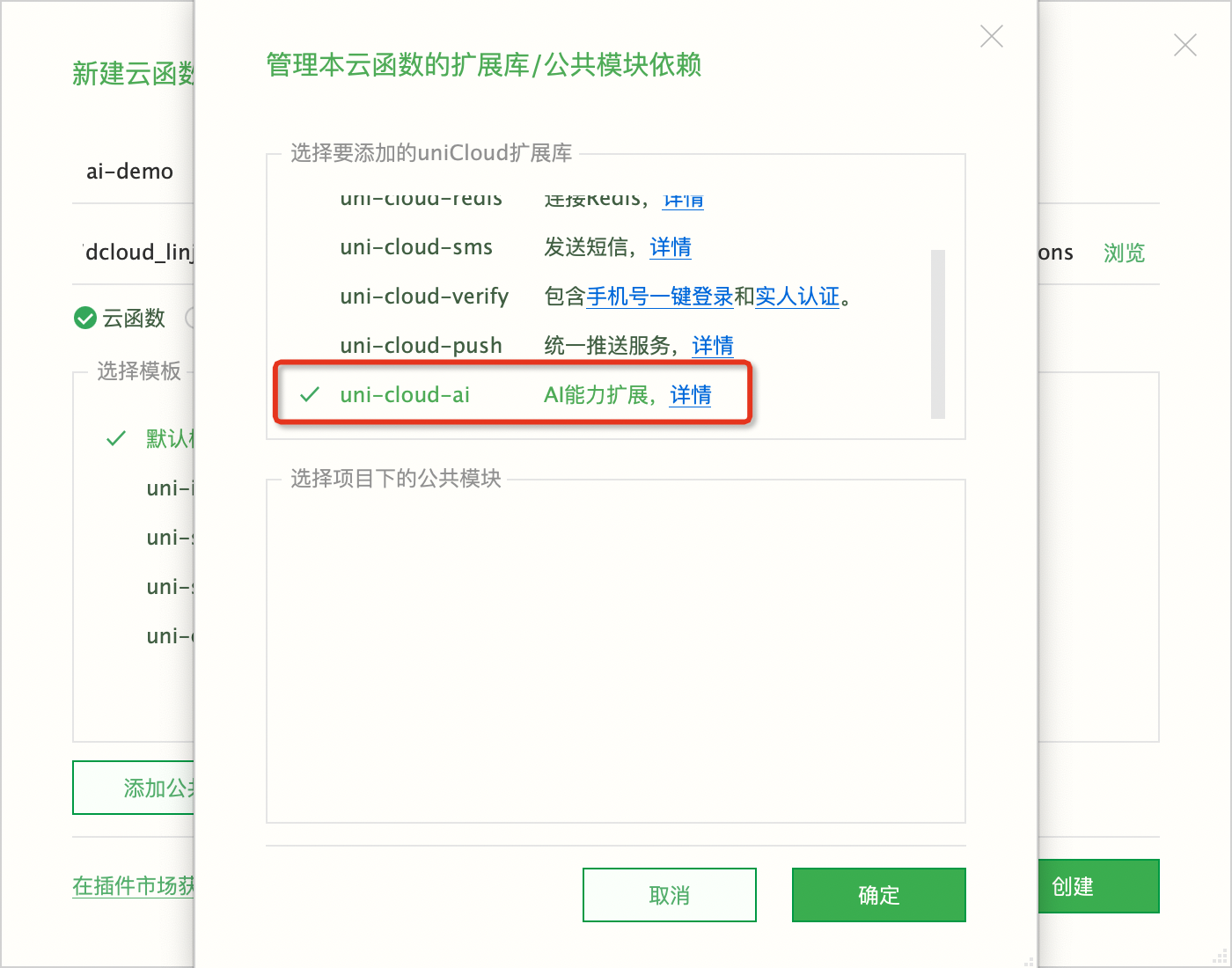
ai-demo。此云函数需要调用uni-cloud-ai扩展库,所以需点击添加公共模块或扩展库依赖按钮。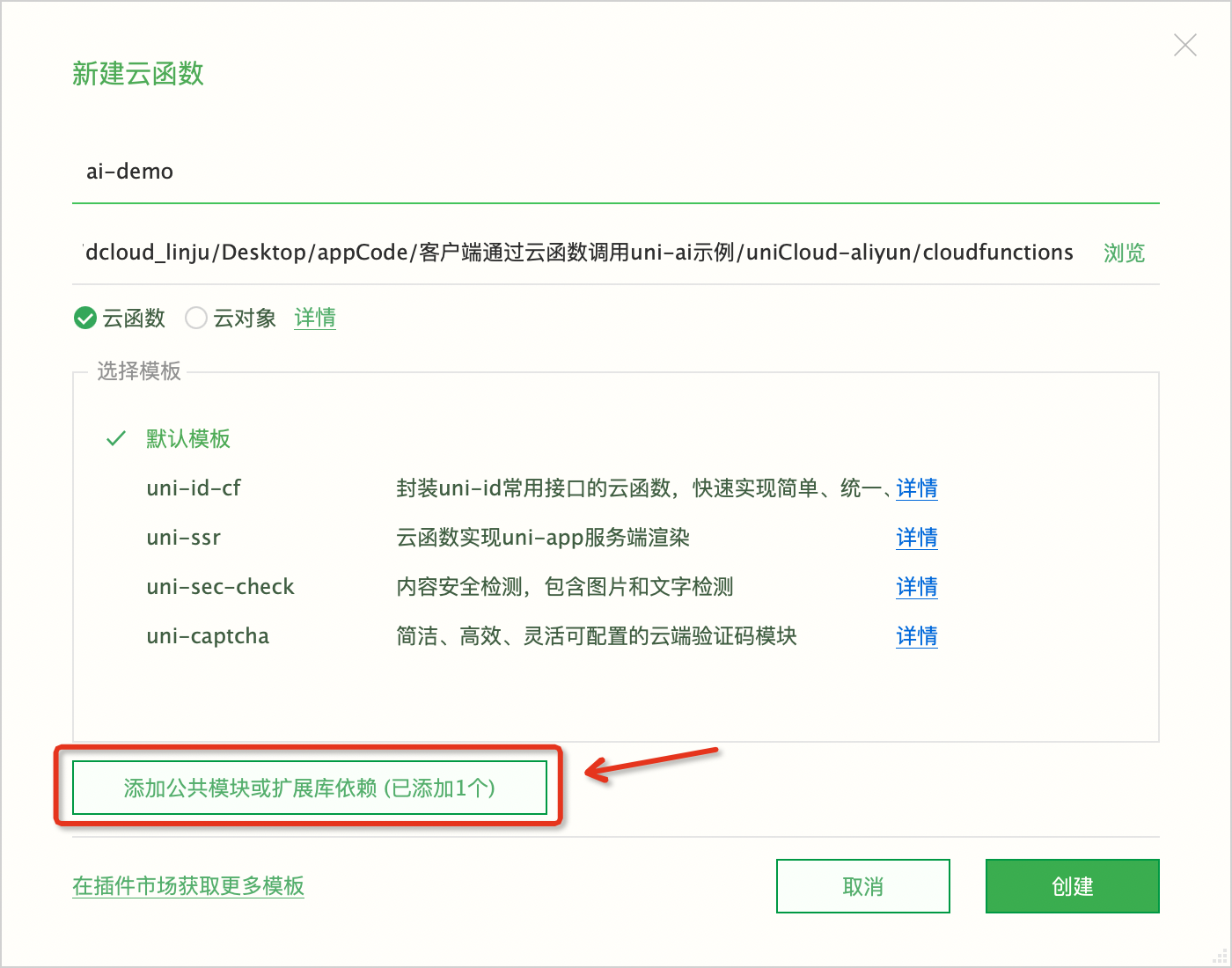
找到
uni-cloud-ai勾选,点击确认,创建云函数
- 云函数中添加如下代码:
// 云函数的代码运行在uniCloud服务器上
console.log('event',event) // event为客户端上传的参数
const {messages} = event
// 校验客户端提交的参数
try{
if(messages === undefined){
throw "messages为必传参数"
}else if(!Array.isArray(messages)){
throw "参数messages的值类型必须是[object,object...]"
}else{
messages.forEach(item=>{
if(typeof item != 'object'){
throw "参数messages的值类型必须是[object,object...]"
}
let itemRoleArr = ["assistant","user","system"]
if(!itemRoleArr.includes(item.role)){
throw "参数messages[{role}]的值只能是:"+itemRoleArr.join('或')
}
const isTextContent = typeof item.content === 'string'
const isMultimodalContent = Array.isArray(item.content) && item.content.every(content => {
return content && typeof content === 'object'
})
if(!isTextContent && !isMultimodalContent){
throw "参数messages[{content}]的值类型必须是字符串或对象数组"
}
})
}
}catch(errMsg){
return {
errSubject: 'ai-demo',
errCode: 'param-error',
errMsg
}
}
const llmManager = uniCloud.ai.getLLMManager({
provider: 'openai',
apiKey:'your key',
proxy:'www.yourdomain.com' //也可以是ip
}) //创建llm对象
return await llmManager.chatCompletion({
messages // 初次调试时,可注掉本行代码,不从客户端获取数据,直接使用下面写死在云函数里的数据
// messages: [{
// role: 'user',
// content: 'uni-app是什么,20个字以内进行说明'
// }]
})
如果不从客户端获取参数,直接在云函数里写messages,可以在云函数中直接按Ctrl+R(或工具栏的运行按钮),在本地运行云函数。
还可以断点调试云函数,详见uniCloud运行调试教程
- 在客户端通过callFunction调用
ai-demo云函数
注意uni-app客户端连接uniCloud不是通过uni.request。如果调用云函数是uniCloud.callFunction。(如调用云对象是uniCloud.importObject)
const content = "你能给我提供什么服务"
uni.showLoading();
uniCloud.callFunction({
name: "ai-demo", // 这里是你的云函数的名称。如果你的云函数不叫ai-demo请自行更换
data: {
messages: [{
role: 'user',
content
}]
}
})
.then(res=>{
console.log(res);
uni.showModal({
content: JSON.stringify(res),
showCancel: false
});
})
.catch(e=> {
uni.showModal({
content: JSON.stringify(e),
showCancel: false
});
})
.finally(()=>{
uni.hideLoading()
})
运行客户端项目,比如运行到web浏览器,即可联调客户端和云端。
上述代码只是最简示例,真正的多轮聊天需要的代码较多较复杂,推荐使用现成的uni-ai-chat或uni-cms。
官方的uni-ai-chat、uni-cms等项目一般不使用云函数,而是使用云对象。想看懂这些项目源码,需要了解云对象
# 非uniCloud服务器调用
如需在非uniCloud的传统服务器调用uni-ai,需要先在uniCloud上创建一个云函数或云对象,加载uni-cloud-ai扩展库,编写上述uni-ai的调用代码。
然后将云函数或云对象进行URL化,转成http接口,详见
注意如果使用URL化后,将无法使用stream流式输出。
如果在您的传统服务器和uniCloud云函数之间需要建立安全通信机制,可使用s2s公共模块,详见
# 从免费版升级到uni-ai计费网关
大语言模型的推理需要消耗很高的GPU算力,调用大模型需要在模型厂商处注册账户和付费。
您可以自行去大模型厂商处注册并填写相应的apiKey的参数。也可以通过DCloud来购买,即使用uni-ai计费网关。
在2023-06-15前,您不填写相关apiKey时可以免费使用uni-ai的LLM能力。但6月15日起需配置自己的apiKey或使用uni-ai计费网关,否则无法使用。
uni-ai计费网关使用门槛低,并且可以一处充值,多模型体验。您无需在多个大模型厂商处申请,只需向DCloud购买token套餐,即可体验各种大模型的效果。
uni-ai计费网关的token计费单价与大模型厂商的定价相同,支持开具发票。
uni-ai计费网关支持调用七牛云大模型服务(支持模型列表)、minimax、微软azure openai ChatGPT3.5的对话接口,调用getLLMManager时如果不传provider会默认使用minimax作为服务商。
购买uni-ai付费服务,购买流程参考:uni-ai开通流程。
更新云函数
- 如果使用uni-ai-chat,更新uni-ai-chat到1.2.0版本,然后上传云对象。如需自定义provider,参考:uni-ai-chat配置。
- 如果未使用uni-ai-chat,直接上传云函数/云对象。如需自定义provider。见上
- 如果客户端通过云函数url化调用云函数/云对象,或开启了uniCloud阿里云的单实例多并发,需要在
getLLMManager方法内传appId参数。见上 - 在使用非流式响应时,
chatCompletion方法无需调整,和免费版用法一致。 - 在使用流式响应时,需要将sseChannel对象传给
chatCompletion方法。详情参考:使用流式响应
调整完毕后上传依赖uni-ai的云函数/云对象即可,注意即使没有修改也需要重新上传。
免费版取消后使用免费版可能遇到的错误
在免费版停用后,如果连接云端云函数时未使用uni-ai计费网关且未自行传递key信息,且未在2023年6月15日0点后更新云函数,则会遇到token is unusable错误。如果使用在2023年6月15日0点后更新了云函数,则会提示尚未购买uni-ai套餐。
此外使用HBuilderX 3.8.4及之前的版本本地运行时无法使用uni-ai计费网关,因此也会遇到token is unusable错误。请使用云端云函数进行调试。
如何测试是否配置成功
在您使用uni-ai计费网关后,且在云函数代码中做好配置后。您可以:
- 运行应用,调用LLM的chatCompletion接口,看看是否返回内容
- 在uniCloud web控制台的uni-ai管理界面,查看计费报表,是否产生了对应的计费条目
使用uni-ai计费网关时,如需本地运行需要使用HBuilderX 3.8.5及以上版本。
# 接入更多大模型或AI服务商
仅支持使用openai sdk的大模型或者AI服务商
# 接入准备
判断要接入的大模型是否支持openai sdk调用,可以在大模型官方文档查看。
在获取getLLMManager实例时provider参数指定为openai,即可接入兼容openai响应规范的大模型。
// 接入硅基流动模型市场内的大模型
const llmManager = uniCloud.ai.getLLMManager({
provider: 'openai',
proxy: 'https://api.siliconflow.cn',
apiKey: 'your key'
})
说明:
- 按照openai sdk的规范,获取实例时应该配置
baseURL参数来指定接入地址,但是uni-ai的openai还未支持baseURL参数,所以需要使用proxy参数来指定接入域名。(此参数预计HBuilderX下次发版时支持)
proxy参数与baseURL参数的区别:
- baseURL为完整的大模型API接入地址,例如:
https://api.siliconflow.cn/v1。 - proxy为大模型API接入地址的域名部分,例如:
https://api.siliconflow.cn,不包含路径的/v1部分。
# 文本对话
model参数(必填)为大模型型号或者时AI服务商提供的大模型型号
await llmManager.chatCompletion({
messages: [{
role: 'user',
content: '你好'
}],
model: "deepseek-ai/DeepSeek-V3"
})
# 交流群
更多问题欢迎加入uni-ai的uni-im交流群 点此加入

